Language
AI+ Telecom Cloud: Trends and Key Technologies
Release Date:2025-05-23
By Zhu Kun
With the debut of ChatGPT, AI technologies have accelerated rapidly, making the intelligent transformation of core network an inevitable trend. As the computing infrastructure platform for the core network, the intelligent transformation of the telecom cloud is a key step in this process.
To meet the high-performance, large-scale parallel processing, and low-latency interconnection requirements of AI model training and inference, the telecom cloud is evolving from traditional CPU-centric general computing to heterogeneous computing centered on DPUs, GPUs, and NPUs. It supports technologies such as computing resource pooling and orchestration, high-performance parallel storage access, high-speed lossless network, and compute-native architecture, ensuring efficient and stable resource provisioning. In deployment, the AI+ telecom cloud adopts hybrid pooling of intelligent and general computing resources and a distributed architecture to better support the intelligent upgrade of the core network.
Resource Pooling Significantly Improves Infrastructure Utilization
Computing pooling leverages software-defined hardware acceleration to enable the more efficient and flexible aggregation, scheduling, and release of massive AI acceleration computing power through capabilities such as GPU virtualization, multi-card aggregation, remote invocation, and dynamic release. It ensures precise end-to-end computing allocation for AI model development, training, deployment, testing, and release, maximizing resource utilization and improving the overall efficiency of the intelligent computing center.
Unified memory pooling, based on the computing bus protocol, achieves consistent memory semantics and spatial addressing capabilities. It integrates multiple physical memory devices or memory resources into a logical memory pool, enabling unified scheduling, monitoring, and management. This technology dynamically allocates and releases memory resources, flexibly adjusting them according to application needs, thus avoiding frequent data movement between compute units and memory devices such as cache, HBM, and DDR during large model training. It improves overall system performance while reducing development complexity and error rates.
Intelligent Computing Storage Meets High Performance and High Concurrency Challenges in Training and Inference
During the various stages of end-to-end large model development, there is a growing demand for innovation in storage, particularly in terms of massive, diversified capacity and high-performance concurrency. Therefore, intelligent computing storage must offer the following features:
- Unified storage platform: Builds a unified storage platform that supports AI processing flows across different phases, providing diverse data storage capabilities and multi-protocol interoperability.
- Comprehensive software and hardware optimization for improved performance: Hardware-level acceleration include offloading storage interface protocols via DPUs, performing operations such as deduplication, compression, and security, and automatically tiering and partitioning data based on access frequency. Software tuning methods include distributed caching, a parallel file access system, and private clients.
- Data entropy reduction: Reduces unnecessary data movement and duplication, and optimizes storage and access policies to reduce the "data entropy tax". Data transmission and storage overheads are reduced through technologies such as deduplication and compression.
Open High-Speed Lossless Network Reduces Parallel Computing Overhead
Parallel computing improves overall computing efficiency in AI large-model training, but it brings synchronization overhead and communication latency. A critical industry challenge is how to achieve high-speed interconnection between GPUs in a super-large-scale intelligent computing cluster to significantly improve GPU utilization.
In scale-up networks, GPU high-speed open interconnection technology based on a switching topology replaces traditional point-to-point GPU communication with a switching-based interconnection mode, enhancing the scalability and communication bandwidth of a single server, breaking the eight-GPU limit, and greatly improving cluster computing power.
The scale-out interconnection network between super-node servers is also important for solving bottlenecks such as communication bandwidth and latency in model training. While RoCEv2 is an open Ethernet-based solution, vendors have generally developed their own enhancements—such as congestion control and end-network coordination—which are often tied to their own switching devices, making decoupling challenging. Therefore, a key industry goal is to provide an open and comprehensive RoCE solution based on RoCEv2.
Compute-Native Technology Enables a Decoupled Ecosystem for Heterogeneous Computing
With the advancement of AI chip technology and manufacturers no longer restricted to a few brands, heterogeneous computing pools based on diverse infrastructure environments and GPU types are becoming the future trend.
Compute-native technology ensures that applications can request computing power based on a uniformly defined intelligent computing value. The compute-native layer provides GPU resources corresponding to the computing value, an interface for resource invocation that shields vendor differences, and an application compilation and runtime environment independent of vendors. This setup shields the underlying heterogeneous GPU resources and fully decouples upper-layer AI framework applications from the underlying GPU type.
Distributed Hybrid Deployment Meets Core Network Applications’ Comprehensive Resource Requirements
Core network NEs require both general and intelligent computing infrastructure resources, while training and inference applications also demand distributed deployment. Therefore, hybrid pooling and distributed deployment of general and intelligent computing resources have become key features of AI+ telecom cloud deployment (see Fig. 1).
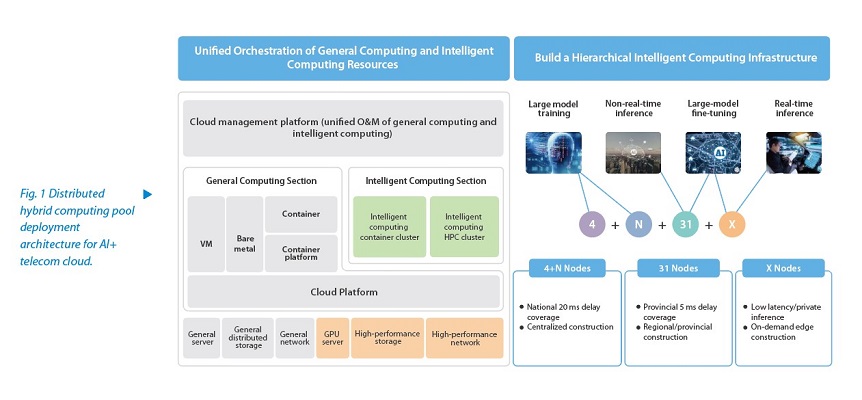
The telecom cloud is seamlessly transitioning from general computing to intelligent computing resource pools, with unified orchestration and management of both as a key feature. A centralized cloud platform typically manages general and intelligent computing infrastructure resources, such as computing, storage, and network, while the orchestration of general and intelligent computing resources is handled by the telecom cloud management platform.
Pre-training of foundational large models, precision tuning of industrial large models, and fine-tuning of large models for customer scenarios all demand varied computing power and deployment locations. In line with the hierarchical architecture of operators’ telecom clouds, the AI+ telecom cloud also adopts a three-level deployment model: a hub-level large model training center, regional resource pools for integrated training and inference, and edge-level all-in-one training and inference machines.
The transformation of the telecom cloud across computing, storage, network, orchestration, and deployment provides an infrastructure foundation for the intelligent evolution of core network services and O&M. With a full range of intelligent computing products and extensive experience in end-to-end intelligent computing center deployment, ZTE is well-positioned to help operators drive the intelligent transformation of their core networks.
Related Articles