Language
DAP Facilitates Commercial Big Data Applications
Release Date:2016-03-16
By Zhu Kezhi
In a less technological era, most information was not recorded, such as the surface color, temperature, and bearing pressure of objects. Even now, only little information can be collected, which chiefly includes data generated by computers and some data selectively received by sensors. Gartner predicts that the global data will reach 40 zettabytes (ZB) by 2020. The rise of big data technologies has brought solutions for data processing, and can allow people to get desirable information and knowledge from the data that they used to discard.
What is big data? Big data features 4Vs: volume, variety, value, and velocity. Big data storage, mining, and monetization are all difficult technical issues that need to be addressed with appropriate solutions. With the development of parallel computing and reduction of hardware costs, parallel computing has been widely used to solve big data issues. Multiple low-cost PC servers can constitute a distributed underlying physical infrastructure, where a distributed file system manages all file systems in a fragmented way and provides standard POSIX file interfaces.
There are different types of big data computing engines for different data and applications. HBase implements rapid query of big data in simple logic; MapReduce provides a variety of distributed service logic through flexible programming; and Spark offers a portfolio of solutions including batch programs. Streaming, Spark SQL, Storm and distributed search engines all support big data applications. These computing engines combined with different analysis and mining algorithms analyze data and uncover value in different scenarios.
To address application needs for big data in various scenarios, ZTE has launched an integrated data application platform (DAP). Open-source DAP includes ZTE’s self-developed manageable, controllable, and highly reliable commercial big data platform. This platform includes data extract-transform-load (ETL) layer, storage and computing layer, open data service layer, mining and analysis layer, and unified management (Fig. 1).
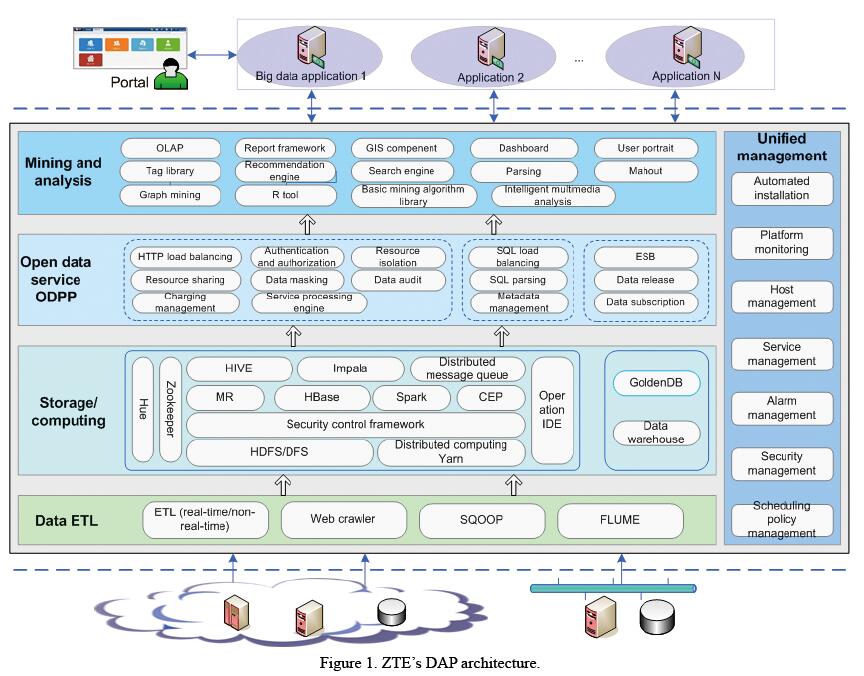
The ETL layer obtains big data for analysis, and it consists of ETL data processing engine, web crawler, sqoop (for database import and export), and FLUME (for distributed log collection).
The storage and computing layer provides engines for data storage, analysis and calculation. This layer contains the underlying HDFS for data storage, YARN for unified management and scheduling of cluster resources, MR for offline tasks handling, HBase for semi-structured data query, CEP for Storm-based complex events handling, and HIVE and Impala for SQL query.
The basic big data platform solves the problems of big data storage and mining. However, the greatest challenge for current big data systems is how to monetize big data. This is also a major concern for enterprises in building big data systems.
To monetize big data systems, it is necessary to build an open transaction platform. An open data processing platform (ODPP) is specially developed on ZTE’s DAP for this purpose. ODPP is the middleware based on universal open source components and developed for data opening and transactions. ODPP consists of multi-tenant management and support, unified SQL, and data exchange and sharing. The multi-tenant component isolates resources and balances the routing load for multiple tenants. It opens data capabilities for each tenant through APIs as required. The unified SQL function allows users not to care the specific engine (whether it is a relational OLAP database or a big-data platform component) for data storage, for ODPP can help them automatically identify data through metadata management and direct SQL statements to a proper storage engine. The data exchange and sharing component enables data transactions by sharing data between tenants. During data sharing, data is transacted, recorded and saved, and transaction CDRs are generated. With these features and a variety of technical means, data application systems can be designed for different business models.
The mining and analysis layer provides mining algorithms and toolkits for developing big data applications, which include OLAP, reports component, basic algorithm library, graph algorithm library, R tools, search engine, recommendation engine, generic text analysis and tag library tools, GIS component, and common visual dashboards.
Unified management ensures consistent management within the framework, involving automatic installation, platform monitoring, host management, service management, alarm management, security management, and scheduling policy management. All this ensures consistent user experience on the manageable, controllable, and operable big data platform.
ZTE’s DAP provides a complete set of big data solutions and has the following features:
● Simplified O&M. The integration and O&M of open-source components is a complex issue. ZTE’s DAP provides automatic batch installation, rich service status display, real-time event alarm, and log trace and audit for easy operation and maintenance.
● Enhanced security management. ZTE’s DAP provides role-based rights management. It supports data masking and remote active-active disaster recovery within a city, so that user data can be fully protected.
● Enhanced open-source components. ZTE’s DAP optimizes configuration parameters on the basis of open sources to enhance performance.
● Open data processing platform (ODPP). Based on open sources, ZTE’s DAP supports unified data opening and multi-tenancy for data sharing and exchange. ODPP provides a basic platform for data transactions.
● Enhanced security management. ZTE’s DAP provides role-based rights management. It supports data masking and remote active-active disaster recovery within a city, so that user data can be fully protected.
● Enhanced open-source components. ZTE’s DAP optimizes configuration parameters on the basis of open sources to enhance performance.
● Open data processing platform (ODPP). Based on open sources, ZTE’s DAP supports unified data opening and multi-tenancy for data sharing and exchange. ODPP provides a basic platform for data transactions.
The acceptance of a big data system by enterprise or government mainly depends on its sustainable liquidity and adaption to changing business models. ZTE’s DAP is a universal big data platform where application systems can be deployed for different business models. It provides technical support for customers to achieve business success.
relative articles