算力光网场景及趋势发展
发布时间:2025-09-23
作者:中兴通讯 谢大
随着人工智能、大数据、物联网等新兴技术的快速发展,算力已成为推动数字经济发展的核心驱动力之一。作为支撑算力资源高效传输与调度的关键基础设施,算力光网的重要性日益凸显。算力光网是为智算中心内部、智算中心之间,以及智算中心接入提供光网络连接,尤其是在智算中心之间的高速直接连接提供Mesh互联的关键技术。本文将探讨算力光网的主要应用场景以及未来发展趋势,以期为相关领域的研究和实践提供参考。
算力光网的主要应用场景
在智算的牵引下,算力光网发展和部署将进入快车道。在智算中心的各种部署情况下,都有光网的踪影,图1为算力光网的总体架构图。
如图1所示,从干线网络到城域网,部署中心DC、区域DC、边缘DC、远边缘DC等设备,这些DC之间通过光网的WDM/OXC网元实现智算网络的连接,根据业务需求实现各个DC的不同带宽的光网络直接连接;区域DC和中心DC的规模较大,要实现智算中心的Scale Up扩展,多个Pod可以通过OXC或OCS(optical circuit switch)实现互联,建设超万卡GPU池;接入网络部署了WDM/OTN设备和超远边缘DC,实现企业入算相关业务,比如联合训练、企业训练数据不落盘、推理和训练结合的业务等。
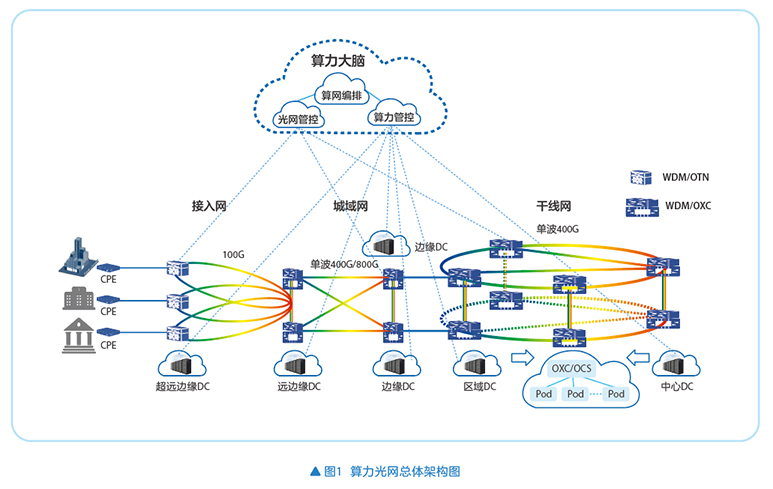
算力光网的智能化管控是实现高效算力调度的关键。通过算网统一编排系统和全光网管控系统,结合算力管控平台(算网大脑),能够实现端到端算网融合业务的资源高效调度和算力服务开通。
智算网络中的高吞吐率还要求端网协同,网络的时延变化、亚健康状态导致的丢包都需要及时同步到GPU网卡的驱动程序的参数配置,根据网络时延及时调整RDMA网卡的参数,并对RoCE网络的缓存进行调整,适配RTT(round trip time)参数的变化,实现智算网络的无损传输,高效利用算力资源。
总体而言,智算中心在硬件加速和技术创新的双轮驱动下,快速发展,会逐步演进为像通算服务一样,将分散到多地的智算中心的多样化GPU卡虚拟为一个超级智算中心,这个超级智算中心用来进行超大规模的联合训练、推理等服务,并可以虚拟为很多的智算业务出租给企业,甚至是个人用户,让人人都用得起智算服务,智算服务像自来水一样随开随用。
目前阶段,算力光网主要包括智算中心互联(DCI)、智算中心内网络(DCN)、算力接入网(DCA)等应用场景。
智算中心互联(DCI)
智算中心作为算力的核心承载节点,其高效互联对于实现算力资源的协同调度至关重要。算力光网通过全光数据中心互联技术(WDM/OXC),实现单纤百Tbps容量的数据中心间全光连接。这种高速互联不仅能够协同调度所有在网算力,应对更高算力诉求,还能有效缓解单一数据中心算力发展的压力,支持客户就近入算。
具体来说,核心智算中心和区域智算中心,一般为东数西算的4+4区域,建设超大的智算中心或智算中心集群,实现万卡以上的智算中心的互联,带宽需求在4:1收敛比的情况下,需要千Tbps的容量需求;与核心智算中心、区域智算中心互联的边缘智算中心,位于地市核心机楼和发达区县的重要机楼,甚至是业务量大的综合业务区,部署1000+GPU卡、100+GPU卡,甚至更少的GPU卡到客户边缘,实现1ms入算。
智算中心内网络(DCN)
在智算中心内部,组网按照1:1收敛组网,网络性能直接影响算力资源的利用效率。算力光网通过引入全光交叉调度技术(WDM/OCS),优化光电融合组网性能和可靠性。该技术能够提升数据中心的算力使用效率,支持大规模并行计算任务的高效执行,降低比特功耗,对端口速率不敏感,网络演进周期变长,应对智算中心内部网络面临的零丢包、低时延、高突发等挑战。
具体来说,就是在智算中心内部各个Pod建网采用OCS和WDM技术,实现单端口百Tbps的容量传输,万卡池互联的4000T的容量需要40对光纤即可实现互联,极大降低了网络的Opex和Capex。智算中心内部网络的GPU网卡的速率每隔2~3年演进一代,而OCS对于速率不敏感,可以支持智算中心网络从200GE、400GE、800GE到1.6TE的平滑演进和混合组网。
当前MEMS-OCS还存在一些技术难度需要克服,比如固定引入3dB~5dB的插损,需要额外放大或者更高功率光模块补偿,插损随通道数线性叠加,使得800G/1.6T模块难以在OCS级联场景下保持光信噪比,限制未来带宽升级,以及目前基于端口的切换时间为10ms级别,达不到光路由的纳秒级别的要求,都是OCS规模应用需要解决的技术难点问题。
算力接入网络(DCA)
算力接入网络是用户接入算力资源的“第一跳”,其性能直接影响用户体验。算力光网通过政企专线的接入技术,支持园区、企业、政府等客户10Mbps~100Gbps速率的高品质灵活入算,实现1ms入边缘智算中心、5ms入区域智算中心、20ms入核心智算中心。
算力光网发展趋势
算力光网的发展还有很多的技术难点和需求需要解决,超高速率传输、全光交换、光网络感知算力业务、AI智能化、低碳和安全可控,以及新型光纤等技术是算力光网未来十年的发展趋势。
超高速光传输技术持续突破
随着流量的持续增长,光网络正不断向更高的速率演进。目前,400G已成为骨干网建设的主流,而800G、1.2T乃至1.6T的T比特时代也正加速到来。目前DSP芯片已经演进到3nm,带宽在1.6Tbps需要Serdes提升到接近450GBd,随着单波速率的提升,频谱带宽也在增加,而单纤的容量并没有得到线性增加,所以发展额外的波段,实现C+L、S+C+L来提升单纤容量,满足智算中心互联的超大带宽需求将是未来需要突破的关键技术之一;调制方式方面,单波速率、子载波或多LANE三者齐头并进,并通过光电集成,如CPO(copackaged optics)方式来提升效率、降低功耗。
全光网络全面普及,感知和端网协同
中长期来看,全光网络将成为算力时代的核心基础设施。通过优化DCA(用户入算网)、DCI(智算中心互联)和DCN(智算中心网络),全光网络将实现更高效的资源调度。全光网是支撑智算中心1ms接入、5ms~20ms智算中心互联,以及微秒级智算中心网络内部各Pod互联的关键场景和技术。
全光网的关键技术是全光交换和相干调谐光模块的技术演进和效率提升、光层全面数字化,以及控制面技术的提升。通过这三大关键技术,智算中心路由向ROADM/OXC/OCS交换同步和更新,实现全光路由、全光业务一次性开通;光纤和光器件全面数字化,实现模拟信号数字化和非线性数据的实时仿真;控制面技术提升,光层业务达到和电层/IP层一样的开通效率,光层的恢复达到和保护倒换一样的指标,业务中断时间小于50ms。
全光网的业务以太网接口,需要支持业务感知,感知客户业务类型、光纤网络的变化和时延等,并根据业务类型来实现业务SLA,进行最优算路选择,根据光纤的变化来实现路径的时延,通知算力管控,并通过算力管控通知RoCE交换机,根据RTT来调整接口的缓存,对于支持缓存和PFC的业务接口,可以自动完成参数调整和缓存大小的匹配,实现100%的吞吐率。
全光网可以实现一跳入算,在接入/汇聚层部署AI算力板卡,实现客户业务就近接入智算中心,实现1ms入智算,赋能OTN专线的客户一跳入智算、安全隔离、高可靠性。
智能化演进
AI技术与光网络的深度融合将成为未来的发展趋势。光网络本身具备良好的管控系统基础,AI化优势明显,AI与光网络的双向赋能是实现网络智能化的关键。
通过AI技术,可以实现光网络实时仿真和实时规划,赋能网络的智能化运维。通过在设备一侧集成GPU,采集光层器件、光纤的在线参数,进行大数据收集,并做专有模型的学习、训练,从而达到光层网络的一次性开通,优化控制面的效率之后,WSON恢复的光层业务可以做到和保护倒换一样的性能指标。
通过AI的运维和优化,可以实现网络运维效率的提升,以及网络资源的合理化应用,提升网络能效,整体降低网络的Capex和Opex。
绿色低碳发展和安全可控
在政策和市场对可持续发展的关注下,绿色低碳将成为算力产业的核心竞争力之一。未来,企业需要通过技术创新(如东数西训)和管理优化来实现节能降碳目标,并推动算力发展从“规模速度型”向“质量效率型”转变。
基于智算光网的大带宽、低时延,以及东西部的电力价差,通过算法来找到一个平衡点,实现西部电力和东部电力、光网络带宽和算力能效的平衡,实现绿色低碳发展。
从安全角度,西部的智算中心作为东部的备份、容灾中心,实现智算中心的安全可控,需要光网络实现智算中心之间的大带宽互通。
新型光纤技术的探索
新型光纤技术(如多芯光纤和空芯光纤)正处于试点建设和传输验证阶段。这些技术有望进一步提升光网络的传输容量和性能,但目前仍需解决批量化制造难题以及现网适应性测试。
空芯光纤可以有较好的频谱效率,将频谱演进到S波分,实现S+C+L的单纤频谱容量,同时可以实现35%光纤时延的降低,是智算中心未来发展的一项关键技术,可以大大提升带宽,降低时延。
作为支撑算力时代的关键基础设施,从智算中心互联到用户接入,从智能化管控到绿色低碳发展,算力光网正不断推动算力资源的高效利用和数字经济的高质量发展。未来,随着超高速光传输技术的突破、全光网络的全面普及以及智能化演进的加速,算力光网将在算力时代发挥更加重要的作用。同时,绿色低碳和新型光纤技术的发展也将为算力光网的可持续发展提供有力支持。
.png)

.png)

.png)


