Scale-Up互联技术
发布时间:2026-03-27
作者:中兴通讯 潘文斌
随着大语言模型(LLM)参数规模从千亿级向万亿级甚至十万亿级的爆发式演进,传统单机8卡XPU服务器的计算资源与显存容量承载瓶颈日益凸显,必须使用大规模服务器集群进行训练。随着集群规模增大,单纯扩大数据并行(DP)维度面临上限。为了继续扩大集群,需要引入张量并行(TP)和流水并行(PP)。当并行域(如TP>8)超出单台服务器的范围时,跨服务器张量并行(TP)成为必然选择,而跨设备的TP All-Reduce通信成为制约大规模分布式训练性能提升的主要瓶颈。同时随着混合专家模型(MoE)在Transformer架构LLM中的规模化应用,更使跨服务器专家并行(EP)成为分布式训练和推理的关键技术需求,而跨服务器的All-to-All通信成为新的瓶颈。
为应对TP和EP对网络带宽与延迟极为严苛的要求,纵向扩张网络(Scale-Up)成为业界主流技术路径。通过Scale-Up网络,可将几十、上百甚至上千张XPU高速互联,构建为超节点(SuperPoD),像一台超级XPU服务器一样实现高效的计算和通信协同能力。Scale-Up不是简单地将多卡进行硬件堆砌,而是需要超高带宽、低延迟的互联技术进行构建。
不同于横向扩张网络(Scale-Out)已经基于Infiniband和RoCEv2形成了业界共识,Scale-Up当前还没有一个统一的标准,呈现出一超多强的局面。NVLink在英伟达(NVIDIA)的Scale-Up垂直整合方案中广泛应用,但依赖单一供应商专有技术所带来的高昂成本和封闭生态、深度的厂商锁定、有限的供应选择,已成为AI基础设施发展的沉重负担。在此背景下,国内外都涌现出多个Scale-Up技术方案:AMD将迭代多年的Infinity Fabric技术开放共享,促成UALink联盟的成立;Broadcom推出面向Scale-Up场景的SUE(Scale-Up Ethernet)以太网方案,并已被ESUN(Ethernet for Scale-Up Networking)确立为该工作组的推荐传输协议;国内字节跳动、北京大学联合设计Ethlink,阿里巴巴、中国科学院计算技术研究所牵头组成ETH+联盟,腾讯、中国信通院在ODCC立项ETH-X,还有设备制造商和芯片提供商推出各自的专有Scale-Up互联协议。
接下来我们从AI网络视角介绍这些“后NVLink时代”的Scale-Up主流技术流派。
UALink
UALink协议由UALink(Ultra Accelerator Link)联盟推动。UALink联盟由AMD牵头,联合行业头部硬件厂商、芯片设计企业,共同参与标准制定与生态共建。
UALink目前有两种规范:基于Ethernet物理层的200G规范,以及基于PCIE物理层的128G规范。
200G规范定义四层协议栈:物理层(PL)、数据链路层(DL)、事务层(TL)、协议层(UPLI)(见图1)。
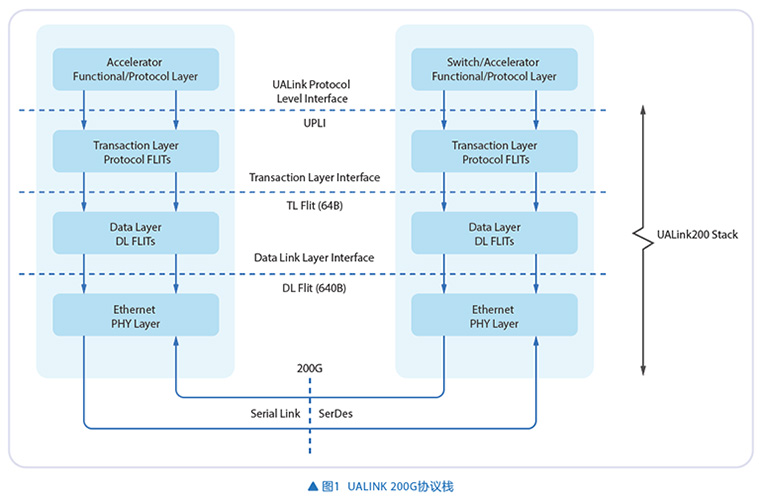
物理层基于标准的802.3以太网物理层,单个UALink通道的最大数据传输速率为200Gbps,也可以降速为100Gbps使用,链路的最大通道宽度为4通道,单个UALink station的最大传输带宽为800Gbps。
数据链路层位于事务层与物理层之间,将事务层下发的64B Flits封装为适配物理层的640字节Flits。该层支持链路级重传功能(link layer retry),以640B Flits为基本单位实现,若接收端CRC校验失败,会向发送端DL发起重传请求。
事务层负责将两个UPLI接口(Originator/Completer)接收方向通道的协议传输转换为以64B为单位的UPLI Flit。此外,事务层还会将从数据链路层接收到的TL Flit,重新转换为UPLI接口上的UPLI通道事务。
协议层定义了一套逻辑信令接口与通信协议,设备可基于此,通过各类请求报文和响应报文完成数据与控制信息的交互。UPLI协议具备原生的灵活扩展能力,支持厂商为同类型加速器间的通信定制私有协议报文。UPLI支持单系统内最多1024个加速器或端点,通过10位标识符完成互联通信。UALink交换机依托这10位加速器源标识符与目的标识符,在发送端和接收端之间转发请求与响应报文。
UALink 200G基于以太网物理层实现,更偏向于GPU之间互联,不支持异构计算设备混联。UALink 128G可以通过PCIE支持混接GPU、CPU、存储。
200G和128G的1.0规范已正式发布,多厂商联盟持续推进生态落地,已形成芯片、IP核等配套解决方案,逐步缩小与NVLink的性能差距。
SUE
SUE协议由博通(Broadcom)主导设计,依托博通在交换芯片领域的技术积累与行业资源推进。
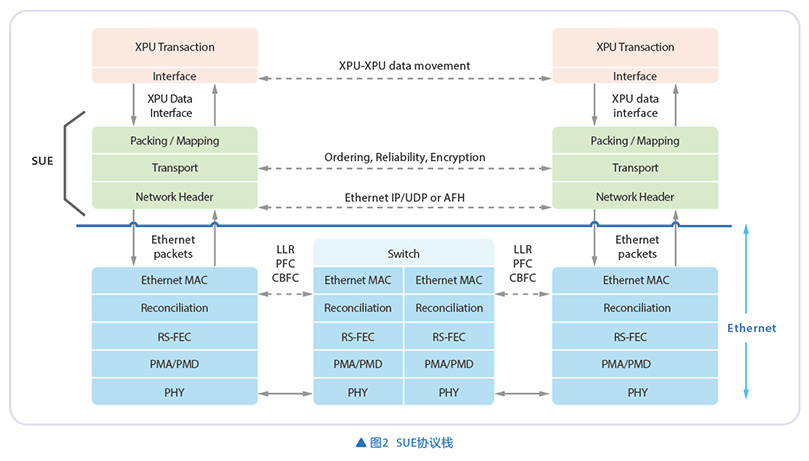
SUE设计目标是支持1024个XPU,采用类AXI的双工数据接口,通过虚拟通道(VC)将事务映射到不同流量类别。其协议栈分为三层(见图2):
- 映射打包层:将发往同一目标(destination,VC)的事务聚合成最大4096B的SUE协议字节单元。
- 传输层:添加可靠性头部(RH),包含序列号(PSN)、虚拟通道(VC)以及确认机制(RPSN),并添加CRC检验。
- 网络层:支持多种报文头,包括标准以太网IP/UDP报文头、优化的AI转发报文头(AFH Gen1)以及高度压缩的AFH Gen2(6B~12B)。
SUE提供三类接口:命令接口,支持FIFO信用机制、AXI4总线,用于传输事务指令和数据(包含操作码、长度和目标XPUID);管理接口,基于AXI的寄存器配置通道;以太网接口,支持200G/100G速率。
ESUN
2025年OCP全球峰会(Open Compute Project Global Summit)期间,由AMD、英伟达、博通、Meta等12家国际厂商联合发起成立ESUN(Ethernet for Scale-Up Networking)工作组,依托OCP组织进行开放治理。ESUN工作组处于规范制定与整合阶段,目标是构建覆盖全数据中心的开放以太网Scale-Up协议栈。参与工作组的成员包括北美AI行业芯片/硬件厂商、大云厂商、开源/闭源大模型厂商等所有重要玩家,未来有望形成产业联盟。
ESUN主要聚焦于网络层和数据链路层,上面的传输层则由SUE-T或其他协议负责。
ESUN定义了新的报文头,将20B的IP头去掉,定义了4B的EH Header,其中包括EH-ECN(和传统IP字段的ECN相同)、EH-QOS(精简版的DSCP)、可用于负载均衡的Flow Label。
EthLink
EthLink(Ethernet Link)由字节跳动牵头设计研发。《字节跳动GPU Scale-Up互联技术白皮书》已经发布,EthLink已在字节跳动AI场景中完成实践验证。EthLink最大支持单跳1024个XPU互联。
EthLink首先对协议栈进行了改造,支持RDMA和L/S双语义:TMA通过DMA Read和DMA Write语义完成Global Memory和Shared Memory之间的数据传输,LSU通过Load/Store语义完成Shared Memory到寄存器之间的数据传输。
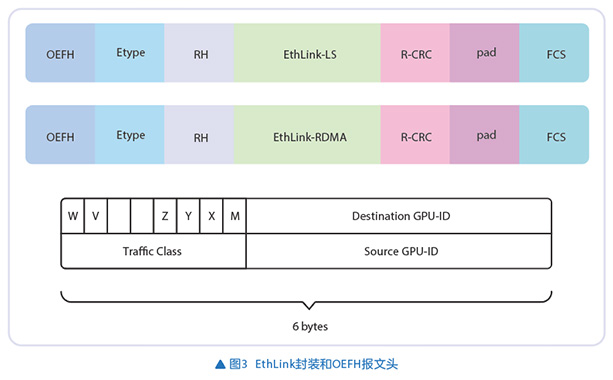
针对传统IP报文臃肿的问题,EthLink设计了极致优化的报文头——OEFH(Optimized EthLink Forwarding Header)。同时构建了一套专为GPU间通信设计的、更轻量级的链路层和事务层协议,使用6B的OEFH进行寻址和转发,进而大幅提升GPU间通信的有效Payload率。EthLink封装和OEFH报文头如图3所示。
ETH+
ETH+由中国科学院计算技术研究所与阿里巴巴牵头,联合行业伙伴成立ETH+(高通量以太网)联盟推进。ETH+的《Scale-Up互连协议白皮书》已经发布,正在推进标准细化与技术落地。
ETH+引入语义适配层,用于桥接上层加速器操作语义与基础网络层之间的差异,将高层的通信操作(如Load/Store、RDMA Read/Write、Send/Receive等)映射为统一的基础通信语义。为高效实现集合操作,协议提供了Reduce、Broadcast、ReduceScatter、AllGather、AllToAll等集合操作专用语义,并将其卸载至Scale-Up网络的交换机或网络接口执行,减少开销。
ETH+基础网络层在协议包头、链路层功能、FCS方面遵循“极简设计”理念:
- 前导码压缩到1B,填充为1010xx11,分别用于同步发送/接收的时钟、映射不同帧类型、标识帧数据起始位置;
- 链路层功能旁路:取消了D_MAC、S_MAC、Type/Len字段,取而代之的是UID base header字段;链路层设备之间的数据帧转发通过识别UID编号而非MAC地址实现;
- FCS简化:ETH+协议允许完全移除帧校验序列(FCS)机制。
ETH-X
ETH-X由中国信通院与腾讯牵头,在ODCC(开放数据中心委员会)立项推进,联合行业伙伴共同研发。目前已完成核心架构与协议规范定义,1.0版本规范已经在ODCC发布,依托ODCC平台推进行业适配。
ETH-X分层架构如下:
- Scale-Up访存协议定义GPU芯片-GPU芯片、GPU芯片-内存池模组的事务访问方式;
- Scale-Up互通协议定义GPU芯片-Switch芯片间的数据包高效可靠传输;
- Scale-Up D2D互联定义计算DIE与IO DIE的物理互联方式。
报文头优化方面,ETH-X设计了新的PRI(packet rate improvement)统一转发头,替代传统以太网的DMAC和SMAC域,共12字节,其中前2个字节为Network DeviceID域,作为网络地址用于网络路由字段,其余10字节为设备地址(User Defined Address),用于设备内部寻址,网络转发节点忽略其内容。
CLink
在国家工信部指导下,中国电子标准化研究院会同北京市经信局联合政产学研用各方,共同发起了计算互联总线协议(CLink)联合倡议,核心目标是提升计算产业全链协同能力。CLink以开源、共研、共享为模式,打造统一的计算互联总线协议标准簇,涵盖总体架构、通信语义、流量控制等关键模块,为大规模智算集群提供统一技术规范。其价值主张为降低集群互联成本与适配周期,提升规模化部署效率,凝聚全产业链共识。
目前CLink已形成初步标准体系,以开源开放智算互联协议为蓝本持续迭代,获得国内产业链广泛关注,正在推进实际场景落地应用,致力于构建自主可控的计算互联生态。
总结
为破解NVLink“一超独大”的格局,业界涌现出了多种Scale-Up方案。主流方案不约而同地选择了基于以太网演进的技术路线,且均针对以太网封装报文头开展了针对性优化,形成了面向AI算力集群的开放互联技术共识。然而,共识之下,开放阵营内部的利益博弈与技术分歧尚未消弭,整体呈现出百花齐放、多元共生的发展态势。
UALink依托多厂商联盟的协同力量,稳步推进互联标准的落地与推广;SUE凭借博通在交换芯片领域的深厚技术积淀,构建起专属的硬件生态优势;ESUN借助OCP的行业组织号召力,统筹跨厂商完成规范的制定与整合;而EthLink、ETH+、ETH-X等方案,则依托国内头部企业与学术机构的实践积累和技术创新能力,走出了独具特色的技术发展路径;CLink由政府部门指导,凝聚全产业链广泛的关注和共识。
未来,在NVLink主导的NVIDIA超节点场景之外,Scale-Up领域的发展走向充满变数:或许国内统一为CLink通用技术标准,或许网络层将由ESUN实现归一化整合,亦或是技术与利益分歧持续存在,长期维持多元竞逐的格局。无论最终走向如何,对于网络领域的科研与工程从业者而言,都无疑是一场值得期待的技术盛宴。
.png)

.png)

.png)


