低时延空芯光纤在跨域大模型训练中的应用分析
发布时间:2026-04-20
作者:中兴通讯 闫宝罗
研究背景
基于Transformer架构的大语言模型(LLM)的出现,对计算资源、存储容量和节点间通信提出了三大需求。即使在NVIDIA A100 GPU的理论峰值计算能力下,使用300万Token的数据集训练1个GPT-3 175B模型也需要32年才能完成。当前一代加速器(如NVIDIA A100/H100)尽管单设备显存达80GB,但仍需至少44块GPU组成的集群才能容纳单个模型副本。因此,LLM的训练和推理通常采用多加速器集群,不可避免地需要在服务器内、服务器间乃至跨人工智能数据中心(AIDC)域进行集合通信。然而,受供电基础设施、AIDC空间限制以及国家计算资源分布的约束,NVIDIA、谷歌、OpenAI/微软等机构已广泛开展跨域协同分布式训练的研究。
一方面,在实际应用中,不同的GPU集群架构和3D并行训练配置具有独特的时延敏感性特征和流量需求。事实上,通过对跨域流量模式和时延敏感性指标进行细致的理论分析,已报道的分布式LLM训练框架在带宽收敛比和分布式训练距离方面仍有进一步优化的空间。另一方面,反谐振空芯光纤(AR-HCF)以空气替代实芯石英介质,从根本上突破了单模光纤传输损耗与时延的瓶颈,目前其降损优化已经历20余年研究,基本收尾,C波段最低损耗<0.1dB/km,优于单模光纤。国内外面向数据中心互联、金融专线等应用场景已有10余处商用部署或试点,例如微软Azure 20km空芯光纤数据中心互联、国内三大运营商港-深低时延空芯金融专线等,说明中短距应用已基本成熟,这吸引业界广泛关注实际业务应用中带来的收益价值。
为了量化空芯光纤系统在数据中心算间应用收益,本研究以千卡集群、在2个地理分离的AIDC间开展LLaMA2-70B模型的优化分布式训练现场试验为例,采用数据并行(DP)和流水线并行(PP)技术,通过理论分析表征了跨AIDC的流量与时延需求。进一步对比单模光纤与空芯光纤应用时算效收益,以此说明大容量光传输(OTN)技术和低时延HCF对未来大规模集群部署的必要性。
LLM跨DC分布式训练算间流量与时延需求
我们分别在2个和3个AIDC间开展了LLaMA2(参数数量ψ=70B)分布式训练实验(见图1)。训练配置参数如下:单GPU计算吞吐量P=122.96 TFLOPS(推算平均值),批大小b=32,序列长度s=4096。集群GPU总数N=1024,全局批大小(GBS)=2048。训练过程中,流水线并行(PP)度p=8,张量并行(TP)度t=8,数据并行(DP)d=16。其中,DP涉及的通信量最大,因此需要计算集群所需的通信带宽BWDP。单批次迭代时间可表示为Tbatch=(6×ψ×b×s)/(p×t×P)=6.99s,单DP迭代时间为。DP中每块GPU每次通信的数据量DDP可近似为2×ψ/(p×t)×2Byte≈4.37GB。进一步考虑DP通信时间TDP,Comm与计算时间TDP,Comm的比值(占总迭代时间的比例不超过5%,通常为1%~5%),可估算出单GPU所需数据带宽。最终,线路侧总互联带宽可估算为3.2~16 Tb/s。因此,我们将跨域流量收敛比设置为1:8,以实现12.8Tb/s的线路侧输出流量容量。该流量可以由16个800Gb/s相干光模块承载,采用单载波135-GBaud PCS-16QAM调制格式的OTN业务传输。单个GPU的Token处理能力(TGS)可清晰反映固定训练数据量下模型的训练速度,其表达式为TGS=(b×s)/(TCal+TCom)/N,其中TCal表示DP或PP的单次迭代计算时间,TCom表示通信时间。TGS可通过测量训练吞吐量得出。随着AIDC间距离的增加,延长的通信时间TCom会导致TE下降。
如图1所示,在2 AIDC分布式训练中,滨江AIDC和吉山AIDC均配置512块GPU集群,AIDC间互联距离在100~600km范围内;在3 AIDC分布式训练中,滨江AIDC部署128块GPU,2个吉山AIDC分别配置512块和384块GPU,仅调整2个吉山AIDC间的互联距离(100~300km)。
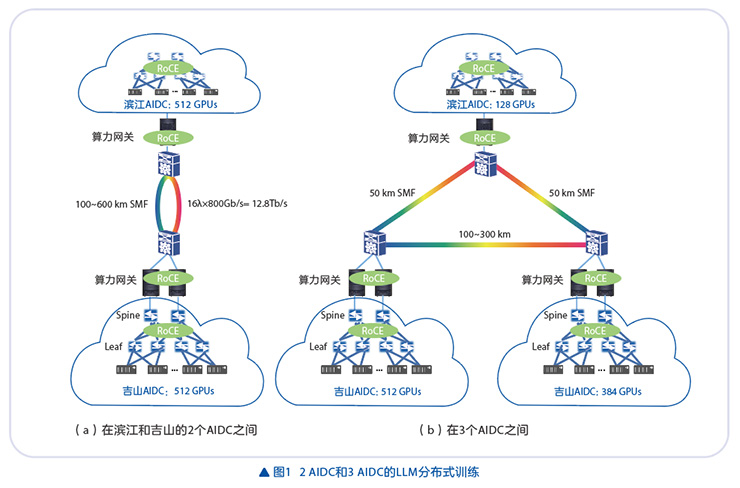
本文以3 AIDC间的分布式训练为例,介绍DP与PP并行过程中数据的流向。在DP并行训练中,数据中心1(DC1)部署8个完整模型副本(DP1-DP8),数据中心2(DC2)部署6个副本(DP9-DP14),数据中心3(DC3)部署2个副本(DP15-DP16)。在采用Ring算法(如ReduceScatter和AllGather)进行DP通信时,跨AIDC通信链路发生在DP8与DP9、DP14与DP15、DP16与DP1之间。在PP并行训练中:DC1包含16个模型副本(DP1-DP16)的PP阶段1-4,DC2部署PP阶段5-7,DC3部署PP阶段8。在PP的点对点发送/接收(Send/Receive)通信中,跨AIDC链路连接PP4与PP5、PP7与PP8、PP8与PP1。除必要的长距离拥塞流控制技术外,在分布式训练中特别采用了分层TP/DP/PP并行技术,以支持全局AllReduce操作,确保总全局通信时间TCom限制在2倍往返时间(RTT)内。对于PP并行,采用了交错式1F1B流水线调度,使通信时间与计算时间能够充分overlay,从而缓解性能损失。最后,通过测量DP和PP并行训练配置下的TGS,表征分布式训练TE损失。
分布式训练性能与空芯光纤对训练算效改进估计
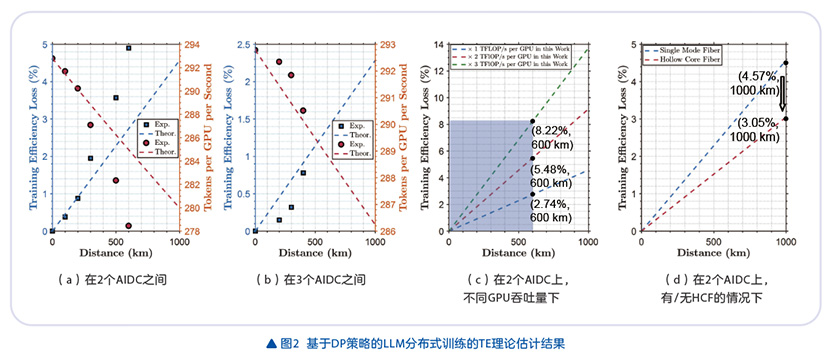
首先,PP并行的测试结果表明,得益于通信时间被掩盖在计算时间,2 AIDC间600km链路和3 AIDC间400km链路的整体TE损失均控制在1%以内(详细数据不在本文展开),因此PP并行对长距拉远时延劣化并不敏感。
DP分布式训练方面,随着2 AIDC间距离增加,TE损失逐渐增大,在600km处达到4.9%,如图2(a)。3 AIDC分布式训练现场实验采用环形拓扑,等效RTT缩短一半,因此在相同AIDC间距离下,TE损失低于2 AIDC场景。基于前文讨论,可对多AIDC分布式训练导致的TE损失进行理论估算,这里仅考虑光传输时延,暂未详细考虑通信时间TCom的其他影响因素,如厂商特定配置(交换机/路由器/OTN设备处理时延、协议开销、流控制处理时间等),这也解释了图2中理论粗估与现场试验结果存在差异的原因。
尽管在此次实验中没有使用空芯光纤,但我们可基于空芯光纤每米降低1.67ns的时延,代入上述推演过程,进一步考虑GPU算力、不同通信距离下评估收益情况。如图2(c),TE损失与GPU实际计算能力密切相关,不同国家地区可部署的GPU算力存在差异,我们假设部署的GPU算力达到此次实验的基准值的2倍和3倍时,计算时间被压缩,通信时延成为性能瓶颈,可以看到超过5%算效劣化场景。另一方面,进一步延长多AIDC间距离将导致算效劣化,因此仍需降低通信时间TCom,如图2(d),我们给出空芯光纤与单模光纤在1000km级2个AIDC下DP并行的算效劣化值,空芯光纤可使RTT减少33%,从而将TE损失改善,这一优势在长途LLM分布式训练场景或高计算容量配置部署中尤为重要。
跨域分布式训练受网络带宽、通信延迟瓶颈等影响,一定程度制约了跨域的距离和集群规模。随着超高速1.6T端口的成熟、超低延迟空芯光纤的部署以及高可靠恢复与保护配置的应用,跨域协同训练将为智算行业快速发展提供强有力支撑。
.png)

.png)

.png)


