GPU、DPU、存储介质协同的新型AI存储架构
发布时间:2026-04-20
作者:中兴通讯 郭伟
随着“Agentic AI”和长上下文模型的快速发展,作为模型“记忆”载体的KV Cache(键值缓存)规模呈爆炸式增长,已成为当前AI基础设施在推理阶段的主要性能与能效瓶颈。传统存储架构主要面向数据持久化设计,难以高效支撑KV Cache这类对性能极度敏感、具有短暂性与可重计算特性的“AI原生”数据,导致GPU资源频繁空转,严重制约了AI工厂的规模化部署与成本优化,AI推理挑战已经从原来的“算力墙”演变为“存储墙”。未来面向智算场景的新型存储架构需要融合硬件创新、网络创新、软件算法优化,突破AI推理瓶颈制约。
AI计算范式转变下的存储挑战
大模型推理分为Prefill和Decode两个阶段。Prefill为计算密集型,处理用户输入提示(prompt);Decode为访存密集型,逐个生成后续Token。在多轮对话中,若不采用缓存机制,历史Token的Key-Value(KV)矩阵需在每次推理时重复计算,造成显著冗余。KV Cache通过将已计算的KV状态缓存于显存中,实现“空间换时间”,避免重复计算,大幅提升推理效率。
当前AI计算范式正经历根本性变革,传统短上下文、单轮交互模式已逐步被长上下文、多轮对话及多智能体(Agentic AI)协同执行的复杂场景取代,表现为三大趋势:
- 上下文长度爆炸式增长:从数千Token扩展至百万级,KV Cache数据量远超单GPU显存容量(如GPT-3的KV Cache可达模型参数占用显存的一半以上);
- 推理即“思考过程”:推理不再是一次性答案,而是一个思考过程,通过测试时扩展提升答案质量,导致生成Token数量年均增长5倍,显著增加KV Cache的读写压力;
- 长短期记忆需求:AI系统需支持跨数周的多轮交互记忆,要求KV Cache具备长期可访问性与高效管理能力。
尽管KV Cache提升了计算效率,但也引发新的系统瓶颈:
- “存储墙”问题突出:KV Cache对带宽敏感,且规模庞大,易成为性能瓶颈;
- 传统存储架构不匹配:现有存储设计强调数据持久化与容错,而KV Cache具有短暂性、可重计算、高频读写的特点,导致其访问路径过长、延迟高;
- GPU资源严重浪费:约30%~40%的GPU计算资源消耗于KV Cache的数据搬运与低效读写,导致GPU利用率不足50%,推高AI推理单位成本。
中兴通讯以“多要素协同”构建新型存储架构
中兴通讯依托近20年来在存储领域软件架构、全自研硬件和芯片技术上持续的技术积累,以及近年来在智算领域的深度参与和思考,推出“DPU+智能盘框+KV Pool软件”的高性能新型存储解决方案。
如图1所示,方案采用以DPU为中心的多级缓存平台的存算分离架构。DPU承担存储协议栈处理、数据高效转发卸载和数据传输优化等关键任务,使得GPU能够专注于业务处理,存储节点聚焦存储低延迟、高带宽的缓存数据。方案提供DPU、RDMA网络、存储智能盘框的端到端纯硬件调优,支持合作伙伴自己的KV Cache存储管理软件“拎包入住”;也可提供不同层面的端到端全套自主可控的软、硬件的新型存储方案。通过软件重构并卸载到计算侧DPU,结合专门设计的KV接口,即消除东西向副本同步流量,方案实现了存储网络带宽的高效利用,同时减少了冗余数据传输,比传统存储网络利用效率提升了3~5倍,数据访问时延降低50%以上。
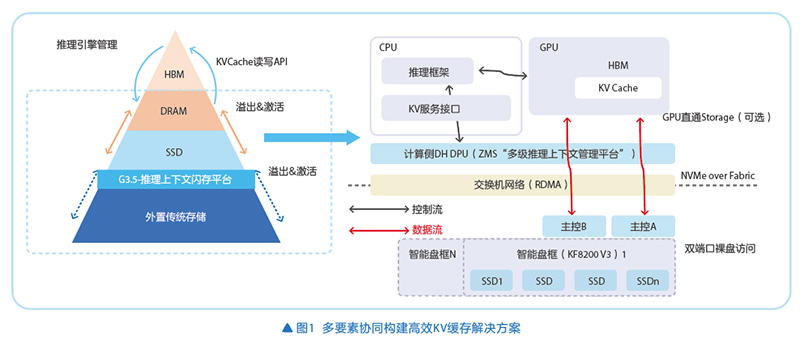
方案采用多项关键技术创新,基于专为智算优化的存储架构将不同存储介质构建分层管理,实现KV数据路径DPU卸载、GPU直通与极简协议交互,配套自研智能调度系统优化,极大提升了长上下文推理效率。
- 多级缓存平台:综合利用DRAM、SSD、远端NVMe盘框分层构建共享池;可分层灵活组合开启,硬件资源占用可灵活调整。
- 多要素协同,构建PoD级的共享上下文记忆空间:专为智算设计的存储智能盘框,支持全NVMe,NVMe-oF接入,裸盘访问;NVMe-oF在DPU硬件卸载转发,KV数据路径计算卸载在计算侧本地,优化数据传输路径;NVMe-oF零拷贝,GPU直通存储协议;重新设计KV Cache PUT/GET专用接口,无协议转化;极简存储架构,去除冗余的元数据管理和强一致性等设计。
- 面向KV的推理调度增强:自研智能KV Cache管理调度系统,优化推理调度算法,实时分析推理请求变化特征,动态调整存储层级与分配策略;设计自适应缓存替换算法,依据数据访问频率与重用概率智能筛选保留或淘汰数据,将缓存命中率提升至70%以上。
随着AI计算范式的不断迭代进化,对AI业务新型存储架构提出更高要求。中兴通讯将继续践行“技术创新,以存助算”的指导思想,持续创新,探索DPU加速、存算一体、先进介质等先进硬件与新型存储架构结合的可行性,构建开放、共享的软件生态环境,协助AI新型存储行业标准构建,为攻克“存储墙”的AI计算范式变革夯实基础。
.png)

.png)

.png)


