Scale-Up/Out/Across三域协同,突破算力上限
发布时间:2026-04-20
作者:中兴通讯 杨茂彬
超大模型时代,模型参数呈指数增长,GPU单卡算力提升缓慢,算力瓶颈已转向系统协同,网络互联成为关键制约因素。Scale-Up架构受限于PCIe带宽,难以满足MoE、TP16~64等高并行需求;Scale-Out通过RoCEv2或InfiniBand构建跨节点网络,承载PP、DP通信,依赖RDMA与AllReduce实现万卡聚合,但面临Incast拥塞、ECMP负载不均、协议稳定性差等问题,导致训练效率下降;Scale-Across实现跨域异构算力池化,核心挑战在于低时延与强一致性保障。单一优化难破局,亟需构建Scale-Up/Out/Across三位一体的高速互联体系,实现带宽、时延、扩展性的协同突破,支撑万卡级高效训练。
智算网络Scale-Up/Out/Across业界现状与问题挑战
当前智算网络围绕Scale-Up(纵向扩容)、Scale-Out(横向扩展)、Scale-Across(跨域互联)三大模式协同演进,支撑万卡级乃至十万卡级智算集群落地。但这三大模式均面临显著技术与产业挑战,适配大模型训练推理仍有瓶颈。
Scale-Up网络聚焦超节点内高速互联,以英伟达NVL72超节点为代表,通过NVLink和NVSwitch实现72卡GPU算力聚合,但NVLink生态私有封闭且与Scale-Out网络无法有效协同。业界也相继出现UALink、SUE、ESUN等总线型和以太型互联技术,整个Scale-Up互联生态较为碎片化,短时间内难以收敛统一。
Scale-Out以RoCEv2为主,从千卡向万卡扩展时瓶颈凸显:首先,传统CLOS拓扑随着节点增多,端口密度与互联带宽呈指数级增长,设备成本与功耗激增;其次,AI流量的突发与聚合导致Incast拥塞丢包在万卡规模下被放大;此外,ECMP负载均衡流量分配不均导致链路忙闲不均,网络吞吐性能无法有效释放;同时,RoCE协议在万卡规模下的稳定性不足,生态碎片化导致不同厂商设备兼容性差,进一步制约扩展效能。
Scale-Across已成为突破单DC极限,实现跨数据中心协同训练的必然趋势。英伟达推出Spectrum-XGS Ethernet跨域互联技术,通过自适应距离拥塞控制、精准延迟管理等特性,将多个分布式数据中心整合为千亿级AI超级工厂。然而,Scale-Across网络长距互联面临RTT高(>1ms)、丢包率高、带宽收敛严重等问题,同时不同智算中心的拓扑、设备、协议不统一,协同调度难度大,跨域算力调度效率低,难以实现全域算力资源的灵活适配。
中兴星云智算网络一体化方案
中兴通讯推出融合Scale-Up/Out/Across模式的星云智算网络一体化方案,以自研芯片为核心,构建“端-机-域”三级架构,实现全链路高速互联,打破网络割裂瓶颈,支撑万亿参数大模型训练(见图1)。
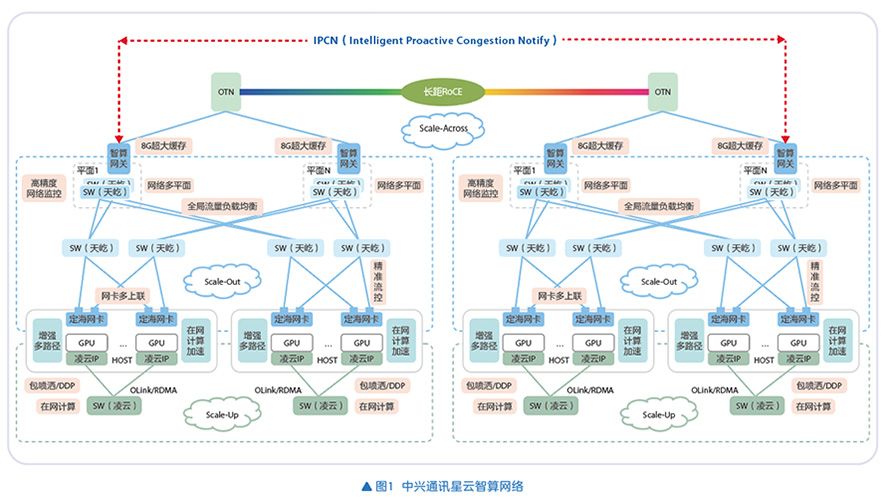
Scale-Up:纵向扩容破局,筑牢单节点算力根基
针对传统PCIe架构带宽受限(<100GB/s)、仅支持8卡互联的短板,中兴通讯依托自研凌云芯片与OLink高速互联总线,创新构建支持32卡及以上超节点的机内互联架构,GPU间互联带宽提升至400GB/s以上,通信时延低至百纳秒级,突破传统TP8限制,适配MoE模型对高吞吐、低时延通信的严苛需求。同时OLink集成在网计算能力,卸载集合通信操作,进一步降低通信时延,有效消除GPU空等现象,GPU利用率提升超40%。
Scale-Out:横向扩容提质,打造高可靠集群网络
基于自研天屹芯片和定海RDMA网卡,星云智算网络方案构建“端网协同”机间网络,实现千卡级到百万卡级无缝扩展。架构支持两种CLOS模式,单PoD支持16K GPU,多PoD可演进扩展至百万GPU,满足未来10年算力需求。针对大规模集群痛点,采用ENCC无损技术确保吞吐率>90%、丢包率<0.0001%,结合iGLB技术实现流量均衡;双平面冗余组网搭配ARN技术,实现亚毫秒级故障切换,保障集群稳定运行。
Scale-Across:跨域互联赋能,织就全国算力一张网
针对单DC算力极限、跨域训练痛点,中兴通讯提出Spine直连+OTN+IPCN跨域方案,助力构建全国级算力一张网。Spine层8GB超大缓存交换机吸收长距突发流量,IPCN技术主动预测拥塞,避免失控;支持多厂商GPU异构互联,单DC可扩展至7个PoD,支撑十万卡级集群,跨PoD收敛比8:1。工程验证显示,300km拉远场景下,1024卡训练算力影响<0.13%,推动“算力即服务”落地。
星云一体协同,打通算网全域价值
星云智算网络一体化解决方案,将Scale-Up、Scale-Out、Scale-Across三大能力深度融合,形成“机内提效、机间扩容、跨域整合”的全链路协同体系,既解决了单机性能瓶颈,又实现了大规模集群的稳定扩展,更打破了地域与厂商壁垒,实现全域算力资源的灵活调度。该方案有效突破智算网络多维度瓶颈,但业界整体仍面临高端芯片自研、生态适配、运维复杂度控制、核心器件成本优化等共性挑战,未来中兴通讯将持续深化技术创新,推动三大能力的更深度协同,助力智能算力网络高质量发展。
中兴通讯以自研定海、凌云、天屹芯片为基石,构建端-网-云全栈自主可控体系,通过Scale-Up、Scale-Out、Scale-Across分别解决单机算力密度、集群规模可靠性、资源协同弹性扩展问题,实现从千卡、万卡到十万、百万卡平滑演进。三域融合在国产GPU关键期突破算力上限,推动中国智算网络从跟随走向引领。未来中兴通讯将深耕算网一体,以星云智算网络助力AI产业迈向全球领先。
.png)

.png)

.png)


