超节点应用场景及技术演进
发布时间:2026-04-20
作者:中兴通讯 毛磊
随着芯片制程放缓和先进封装在散热、良率、成本等方面逼近当前工程能力上限,单点算力提升难以为继。为应对大模型所带来的算力爆发式增长和分布式并行计算需求,超节点应运而生。超节点通过高速互联将众多GPU整合为一个逻辑统一、调度高效的计算单元,像一台“巨型服务器”一样协同工作。
超节点定义与技术特征、价值场景
目前业界对超节点的概念尚无明确的描述,相关标准尚在制定过程中。但不同联盟、厂商定义或实现的所谓超节点,相比传统智算服务器产品或方案具有以下软硬件共性技术特征:
- 大量GPU互联系统:由于业界已经有成熟的8卡产品方案,因此超节点超过8卡是最基本要求。
- 统一内存地址空间:为互联的GPU提供统一寻址和内存一致性,如英伟达UVA(unified virtual address)、UM(unified memory),系统内任一GPU可以像访问本地HBM(high bandwidth memory)一样访问任意互联的HBM。
- 超高带宽、超低时延互联:除PCIe/CXL外提供额外GPU显存高速互联,如英伟达NVLink,为系统内GPU提供高速访问的物理通道,带宽达数百GB到数百TB,纳秒级时延满足GPU间内存语义通信的同步操作要求。
- 原生可扩展性:互联协议层面预留相应的bit位数满足未来可能的GPU扩展规模,拓扑层面支持一级和二级交换实现更大集群规模的扩展。
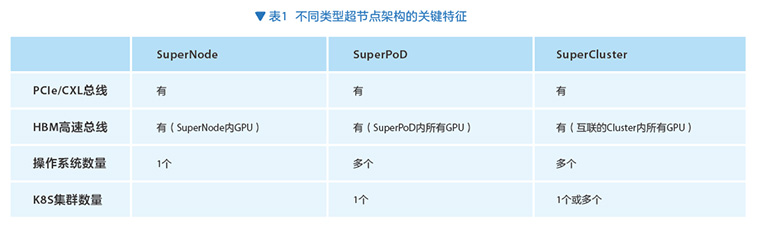
根据不同类型超节点的其他关键技术特征差异(如操作系统粒度等),通常可以把超节点分成三类:SuperNode(超级节点)、SuperPoD(超级单元)和SuperCluster(超级集群)。一般SuperNode至少支持16卡GPU以上互联,SuperPoD可支持成百上千GPU,而SuperCluster支持的高速互联GPU数量更多,对应的架构如图1所示。各类型超节点架构的关键特征如表1所示。
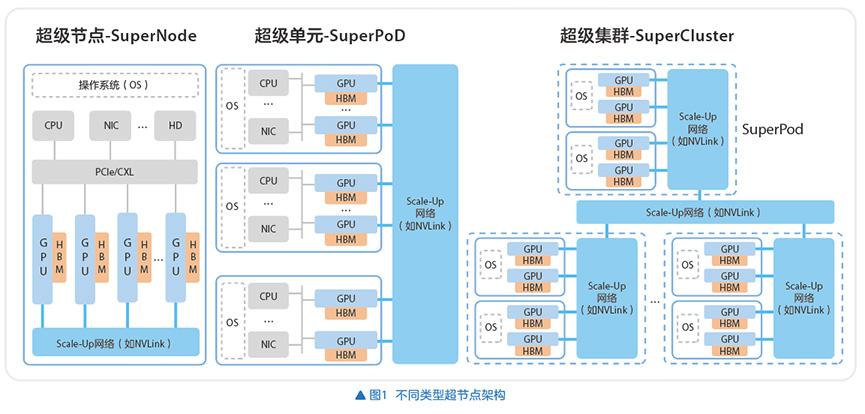
超节点能够提升大规模参数模型的训练效率,并优化推理性价比。
- 提升大规模参数模型训练效率
超节点为TP、EP等复杂并行计算提供强大的硬件支撑,缩短通信传输时间,提升集群并行计算效率,能够更高效地支撑超大模型训练,缩短训练周期。
然而,超节点规模的选择需结合训练需求权衡性能与成本,根据阿姆达尔定律,系统中不可并行部分会限制扩展带来的加速收益,且伴随复杂度、能耗与容错成本上升。基于Qwen235B在不同超节点形态下最优切分各部分耗时分析,在2000卡集群中,增大超节点规模可提升性能,主要受益于MoE算子优化,但存在边际效应,64~128卡是性能甜点区,当超节点达128卡后,性能增益趋于平缓。
- 优化每Token推理性价比
推理关注单位成本性能和用户体验,超节点以高速互联、内存池化、高度集成等优势,能够精准适配推理高并发、实时交互和大显存消耗需求。
随着DeepSeek、GLM等大模型参数规模突破千亿甚至万亿,通过超节点来承载大模型跨机推理,解决单卡显存不足与通信瓶颈,可有效缩短任务响应时间,提升吞吐量。此外Agentic AI、长文本对话、复杂文档分析等场景,推理过程中产生的KV缓存随上下文长度线性增长,超节点通过全局内存池化实现KV缓存的共享与复用,可支持处理数十万甚至上百万Token的上下文,极大增强其理解复杂问题、执行长期任务的能力。
国产超节点技术演进思考
当前国产超节点呈现多架构、多形态发展的态势,产品与技术仍处于快速迭代阶段。其技术演进脉络可从产品架构、物理连接、系统生态三个维度展开分析。
产品架构层面,通过单柜极致密度和多柜互联两条路线提升规模。单柜极致密度以英伟NVL576为典型代表,凭借技术领先性和供应链话语权,英伟达牵头产业界合力攻坚兆瓦级机柜关键技术难题,如800V高压直流供电、全液冷、中置正交背板等。考虑到英伟达GPU单卡算力领先优势,从NVL72到NVL576,其单柜极致密度路线可以匹配模型的演进需求,而国产AI芯片性能与之存在代际差距,加之先进工艺受限,短期内难以追赶。除了提升单柜GPU密度外,可进一步采用多柜互联扩展,通过规模领先另辟蹊径,利用成熟工艺将高带宽域纵向以机柜为单元扩展至数千规模。
物理连接层面,从电互联向光电融合一体化演进。电互联因低成本、高可靠、低时延等特点,是短距通信首选,尤其单柜内组网电互联优先。随着超节点Scale-Up域规模扩大,引入跨机柜互联场景,光互联技术以其独特的优势脱颖而出,如能够克服电互联距离限制、实现更高速的数据传输以及有效避免干扰等。以LPO、NPO、CPO等为代表的光互联技术方案将长期共存与互补,从互联带宽发展、生产良率、可维护性等角度看,预计呈现国际CPO领跑、国内NPO优先规模落地的差异化演进节奏。
系统生态层面,聚焦开放解耦与软硬协同。开放解耦包括超节点内部计算节点和交换节点解耦,以及CPU和GPU资源的解耦,同时聚焦构建统一的高速互联协议,规避私有封闭互联技术带来供应链依赖和成本方面的风险。软硬极致协同设计提升算效,集成更多类型的异构芯片,CPU、GPU、DPU、NIC等多芯协同,软件原生适配超节点网络拓扑,通过智能编排实现训练与推理高效切换,满足池化资源灵活切分,结合全流程软件优化,提升算效与系统稳定性。
中兴通讯超节点产品创新
基于对整机柜超节点方案的深度工程实践,中兴通讯Nebula超节点创新提出OEX(Orthogonal Electrical eXchange)正交无背板互联交换架构,以Matrix集群满足规模扩展需求,同时积极打造开放解耦的软硬件生态体系。
OEX架构创新
OEX是一种正交无背板互联交换架构,其核心在于实现计算托盘与交换托盘之间的垂直交叉物理连接,消除传统线缆托盘(Cable Tray)带来的信号损耗与可靠性风险。该架构通过简化互联路径、提升信号完整性,为构建高密度、高可靠性的单体超节点提供物理基础(见图2)。在超节点设计中引入OEX架构,通过正交连接器与单级交换拓扑,实现计算节点与交换节点之间的垂直交叉互连,从而彻底摆脱了传统线缆的束缚。在高速信号完整性、可靠性和可维护性方面相比传统的线缆托盘方案更具优势,也为后续架构扩展和演进预留了足够的空间。
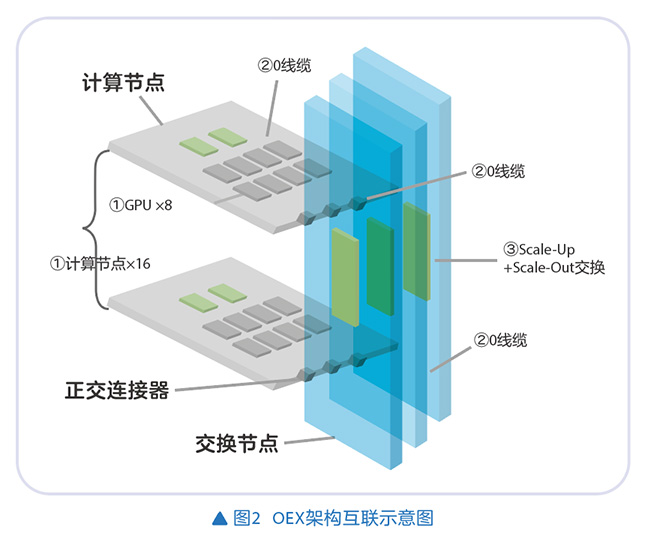
Matrix集群可扩展
当前主流集群超节点部署方案多采用电交换+光互联架构,该架构技术成熟,生态完善,兼容性强。基于该技术方案,中兴通讯现有Nebula X32单体超节点可灵活扩展,构建形成Nebula Matrix X256/800集群超节点;面向未来,依托更高密度的Nebula X128单体超节点,更可进一步扩展至Nebula Matrix X8192/16384超大规模集群,充分满足超大规模模型训练的算力需求。中兴通讯并未止步于此,而是积极探索光交换与电交换的互补协同,旨在融合光传输的高效与电交换的灵活,以支持未来超大规模集群的可扩展性需求。
开放的软硬件生态系统
中兴通讯积极推动国产AI算力底座的标准化进程,硬件层面全面开放OEX机械与电气接口规范,支持第三方计算及交换托盘的即插即用,有效降低系统集成门槛,促进产业链的协同创新。由中兴通讯主导的正交超节点整机柜设计规范已在ODCC官网正式发布。
软件层面,中兴通讯打造OLink开放高速互联协议,在底层兼容以太网的同时,通过物理层和事务层创新,满足Scale-Up高性能互联与Scale-Out超大规模扩展的双重需求,支持纳秒级延迟、统一内存编址与在网计算,显著降低组网复杂度与成本,并兼容多元GPU生态。
在芯片摩尔定律趋缓的背景下,超节点凭借架构创新、极致互联与软件优化,持续突破算力瓶颈,推动计算体系由芯片级摩尔向系统级摩尔迈进,未来有望成为构建AI基础设施的核心底座单元。
.png)

.png)

.png)


