多要素协同进化,筑牢AI时代算力底座
发布时间:2026-04-20
作者:中兴通讯算力及核心网产品首席规划专家 郭雪峰
在新一轮科技革命与产业变革浪潮中,人工智能已成为重塑全球竞争格局的核心力量,不仅深刻改变着千行百业的生产范式,更跃升为为国家科技战略博弈的关键制高点。
当前,我国人工智能产业虽在算法创新、场景应用等领域取得显著成绩,但在算力基础设施层仍面临先进算力代际差距、异构算力生态协同不足、算力资源利用率偏低等多重挑战。本文面向人工智能长期发展,探讨国产智能算力普惠发展路径。
人工智能规模落地发展,亟需普惠算力支撑
算力是人工智能发展的基石,大模型作为当前人工智能发展的核心载体,其迭代速度与落地广度,始终受到算力资源可及性与成本的约束。无论是基础大模型的预训练还是行业大模型的定制化开发,都需要海量算力及巨额成本支出。随着我国“人工智能+”战略的深入拓展,AI应用以及AI Agent快速发展,推动推理算力需求爆发式增长。据IDC预测(见图1),我国智能算力规模未来三年仍将实现翻倍增长,智能算力成本的持续优化和降低程度,将直接决定人工智能赋能产业化长期发展的成效。
无论是大模型的迭代演进,还是Agent的场景化落地,都离不开普惠算力底座的支撑。算力成本的降低还将进一步打破技术创新的成本壁垒,促进人工智能技术持续发展,激活AI与千行百业的结合,让人工智能真正服务于每个人、每个场景,实现“技术向善、普惠共生”的发展目标。
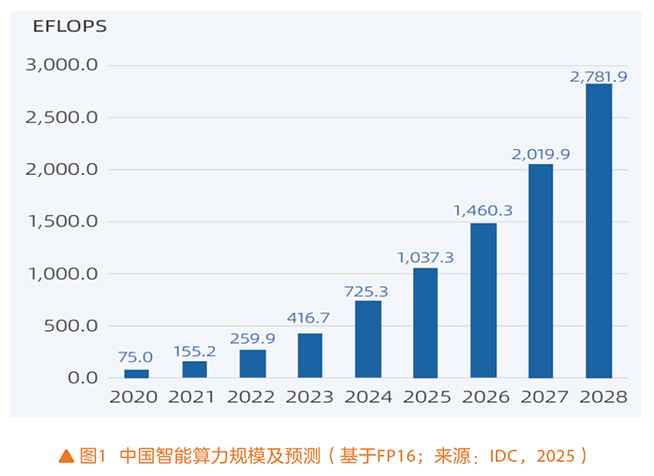
算存网软能多要素协同,构建最优TCO算力底座
大规模数据中心是人工智能与实体经济深度融合的核心算力载体。在后摩尔时代,要真正发挥这一载体价值,依赖算力芯片迭代演进、算力集群规模扩张,虽可实现算力规模优势,却难以有效释放GPU算力潜能、降低算力成本。通过算力、存储、网络、软件、能源多要素深度协同,破解通信墙、存储墙、能耗墙,提升AI工厂算效与能效,打造最优算力TCO,已成为当前国内外产业界的普遍共识。
在国内,软硬协同、模芯协同已步入规模化落地阶段。产业端通过架构革新、算法优化与工程实践实现算力效率跃升。例如,行业内依托P/D分离与KV缓存实现算力与存储的协同,提升推理计算效率;通过通信计算重叠的Overlap调度技术,消除算力运行空泡,提升并行计算效率;基于MTP多Token预测算法优化大模型推理解码流程,突破单Token串行执行的效率限制。在海外,英伟达Rubin平台通过系统级的协同设计和优化,整合Rubin GPU、Vera CPU、NVLink 6、Bluefield DPU等核心硬件实现极致协同,单Token推理成本降至前代的1/10,高效支撑超级AI工厂落地。国内外实践探索充分印证,多要素协同进化是构建先进AI算力底座、实现最优TCO的关键途径。
我国智能算力建设在高端芯片获取受限的挑战下,已逐步走出一条依托算法、工程与算力协同的“经济高效型”差异化发展路径,但相对国际先进水平仍存在明显短板,算效能效偏低。
- 算力芯片存在代际差距
AI芯片厂商多而不强,受限于先进工艺制程,在算力、显存、显存带宽等核心指标上与国际头部厂商存在代际差距。单纯依靠芯片自身迭代难以快速补齐短板,更需通过系统性架构创新,以网络传输优化、存储性能提升、软件栈适配升级与算力的深度协同,最大化释放芯片的算力潜能,实现“以协同补差距”的系统突破。
- 生态割裂制约协同落地
当前智算产业生态碎片化问题突出,芯片厂商主导形成大量相互独立的垂直生态,推高了模型算法与算力的迁移适配成本,跨厂商的算力、网络、存储间难以实现高效协同联动,重复开发与厂商锁定导致产业发展成本高、投入大。
- 孤岛现象普遍,算力资源利用率偏低
据统计,当前我国已建成数十个万卡智算集群以及大量的中小规模算力集群,智算规模跃居全球第二。但算力集群间互联互通壁垒高,一方面无法聚合形成大规模算力集群满足大模型训练需求;同时面向多场景的推理需求,算力集群间资源调度协同不足,导致算力资源配置局部失衡,整体资源利用率偏低。
从算力需求看,大模型全生命周期覆盖预训练、微调、强化学习等多元场景,算力需求呈现规模跨度大、动态波动强的特征:基础大模型预训练需要超万卡大规模集群支撑,训练期间独占资源,而模型微调、二次训练则以百卡级中小集群算力为主,需求灵活分散。推理算力正朝着轻量化、高效化、场景化方向转型,不同场景对算力的需求差异大。算力建设及供给需要与时俱进,从规模优先向效率优先演进,持续优化算力成本,推进产业普惠发展。
构建统一开放生态,推动全链条系统性协同创新
破局之道在于以开放统一生态、多要素协同进化、跨域算力互联互通为手段,实现系统性的架构优化与创新,构建先进AI智算底座:以开放架构解耦生态壁垒,构建国产化智算统一标准,实现国产芯片、软件栈、模型的迁移适配,降低生态碎片化成本;通过系统级架构创新,实现网络、存储、算力的高效协同,以网强算,以软补算,以集群算力优势弥补单芯片性能短板;构建算力互联互通网路,整合跨域算力资源,形成 “算力分布式部署、一体化编排调度,资源动态聚合”的顶层算力格局,最终实现从单点技术追赶向生态体系突围的战略转型(见图2)。
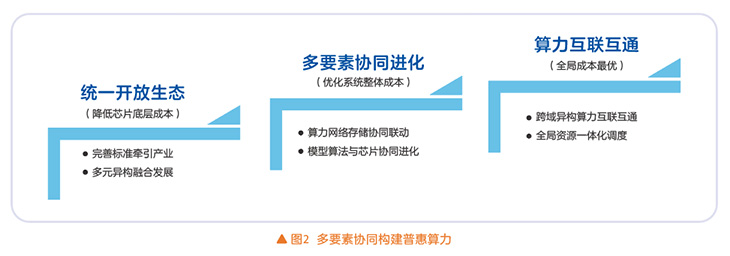
统一开放生态,推进多元算力发展
面向大模型全生命周期业务场景,构建国产智算统一标准体系,开展异构算力互联互通、混训混推等核心技术攻关与工程实践,形成标准化、可复制的技术解决方案。依托开放统一的智算生态框架,推动多元国产芯片协同适配、有序发展,精准支撑超大规模训练、轻量化推理、边缘智能等多元化场景需求,为普惠算力规模化落地筑牢健康可持续的产业生态根基。
多要素协同进化,释放极致算力效能
系统架构层面,强化算力、网络、存储、算法、模型全要素协同联动机制,并将协同设计贯穿算力基础设施建设全流程。优化参数面网络性能降低通信开销、内存外存一体池化破除存储壁垒,探索模型算法与国产算力特点适配机制,持续优化算力容错与故障恢复机制,以全要素协同升级推动算力基础设施整体迭代,打造规模、算效、能效领先的先进数据中心。
算力互联互通,实现全局TCO最优
建设算力互联互通网络,突破跨域异构混训、一体机编排调度等技术瓶颈,通过跨地域跨厂家算力集群动态聚合与协同调度,实现算力碎片化利用,并能支撑超大模型规模化训练需求。推进全国一体化算力资源监测及调度体系建设,结合AI业务场景特性实现算力资源精准高效调配,构建云网边端协同的分布式智算体系,推动算力资源全域共享、利用率最优。
人工智能作为引领新一轮科技革命和产业变革的核心力量,正深度赋能千行百业,成为驱动数字经济高质量发展的关键引擎。只有持续推进产业生态开放、算力架构革新、全要素协同进化,降低人工智能全生命周期使用成本,让高效算力更可及、更易用、更普惠,才能真正打破技术与成本双重壁垒,推动人工智能从高端示范走向全域普及,实现人工智能普惠化、高质量发展的最终目标。
.png)

.png)

.png)


