云计算分布式缓存技术及其在物联网中的应用
发布时间:2011-07-20
作者:高洪,董振江
多网融合、低碳节能、物物互联及移动互联网,这些当今社会的热点需求,催生了云计算技术的发展;随着PC性能提升、成本下降以及网络技术的发展,构建分布式的业务计算环境比集中的大型机的业务环境更具有成本和技术优势,为云计算的发展提供了强大的技术驱动力;Google,Amazon,Salesforce等IT巨头更是推出了基于云计算的服务,并取得了巨大的成功,让人们看到了云计算所带来的巨大优势和影响力;这也让世界各国政府对云计算的发展的非常重视,中国政府在“十二五”信息规划的技术背景中特别对云计算技术做了阐述,明确提出云计算技术是中国下一个五年信息化产业发展的重点领域之一,为云计算的发展提供了政策驱动力[1-2]。
正是在这样的需求、技术、应用和政策的背景下,云计算成为IT业界共同认可的主流声音。云计算其实就是把所有的计算应用和信息资源都用网络连接起来,供个人和应用随时访问、管理和使用。云计算服务提供资源,包括计算、存储及网络资源,需要能够实现海量的存储、出色的安全性和可靠性;云计算提供的服务应该是动态的、可扩展的,能够根据用户和应用的规模进行动态伸缩,并且这种伸缩所需要的时间是短暂、迅速的;云计算平台应该能够提供开发应用程序编程接口(API)、环境和工具,供各种应用进行使用。只有这样云计算平台才能够和应用很好地结合起来,使得传统的集中式应用方便地迁移成高性能、高可靠且易扩展的分布式的云计算应用,为用户提供类型多样的云服务。
云计算是物联网发展的基础。互联网主要解决人与人的互联,连接了虚拟与真实的空间;而物联网主要解决的是物与物之间的互联,连接了现实与物理世界。物联网是以互联网的发展为前提的。随着物联网应用的发展、终端数量的增长,会产生非常庞大的数据流,这时就需要一个非常强大的信息处理中心。传统的信息处理中心是难以满足这种计算需求的,在应用层就需要引入云计算中心处理海量信息,进行辅助决策。云计算作为一种虚拟化、分布式和并行计算的解决方案,可以为物联网提供高效的计算能力、海量的存储能力,为泛在链接的物联网提供网络引擎和支撑。
1 分布式缓存的发展
在互联网应用刚起步时,各种平台大多采用的是关系型数据库。那时PC机昂贵、性能低下并且网络不普及,而关系型数据库因为处理能力强、数据安全可靠、一致性好等优势,一直处于主导地位,并发挥了重要的作用。随着互联网的发展,特别是WEB 2.0等交互式、个性化应用的出现,数据量急剧增加,传统的关系型数据库已经无法满足这种快速增长的存储需求。为此不少IT服务提供商都设计开发了自己的存储系统,如亚马逊在2007年10月份开发出的Dynamo就是其中非常典型的一种存储系统(如图1所示),作为状态管理组件和存储服务的基础被用于众多的亚马逊的系统中[3-4]。
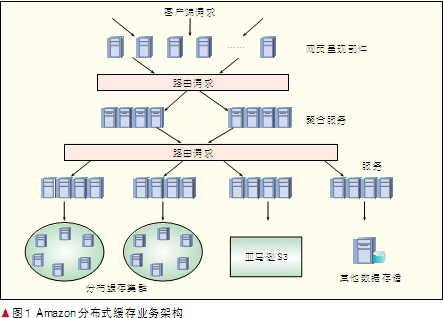
对于Google,Amazon,淘宝这样的互联网企业,每时每刻都有无数的用户在使用它们提供的互联网服务,这些服务带来的是大量的数据吞吐量,在同一时间,并发的会有成千上万的连接对数据库进行操作。在这种情况下,单台服务器或者几台服务器远远不能满足这些数据的处理需求,单靠提升服务器性也已经改变不了该情况,所以唯一可以采用的办法就是扩展服务器的规模。服务器规模扩展通常有两种方法:一种是仍然采用关系型数据库,然后通过对数据库的垂直和水平切割将整个数据库部署到一个集群上,这种方法的优点在于可以采用基于关系型数据库(RDBMS)的技术,但缺点在于它是针对特定应用,实施非常困难;另外一种方法就是Google和Amazon所采用的方法,抛弃关系型数据库,采用Key-Value形式的存储,这样可以极大地增强系统的可扩展性。事实上,基于Key-Value的分布式缓存就是由于Google的BigTable,Amazon的Dynamo以及Facebook的Cassandra等相关论文的发表而慢慢进入人们的视野,这些互联网巨头在分布式缓存上的成功实践也使之成为了云计算的核心技术[5]。
2 分布式缓存技术
2.1 分布式缓存的部署方式
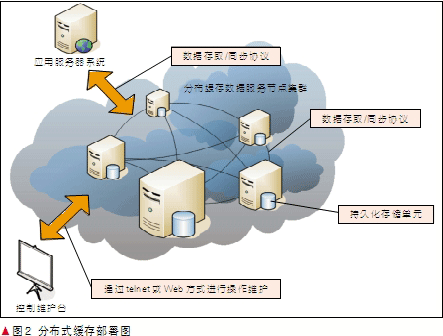
缓存服务器集群采用无主架构,所有服务器节点地位完全一致,互相之间采用网状的全连接方式。应用通过调用分布式缓存提供的API对数据进行透明访问,无需关心数据在后端服务节点的分布情况。数据在集群各节点均匀分布,集群数据处理能力随集群中节点数量的扩充呈线性增长。集群通过数据的多副本机制能够提高系统的可用性,某几台服务节点的宕机对应用的数据访问没有任何影响。服务器节点能够根据应用的需求灵活配置数据是否持久化存储。
分布式缓存同时提供操作控制台,能够登录到任何一个服务节点并对集群的成员关系、访问负荷、数据分布进行监控和配置,同时通过操作维护台可以完成分布式缓存集群软件版本的安装、升级和配置。目前分布式缓存提供基于命令行(telnet登录)和基于B/S的图形化运维方式。分布式缓存系统的具体部署如图2所示。
2.2 分布式缓存功能架构
分布式缓存为应用程序提供了客户端程序库以及若干数据服务节点组成的服务集群,客户端通过和数据服务节点通信形成可用服务器列表,并将应用程序提交的存取请求通过路由算法映射到一个确定的数据服务节点上,具体的功能架构如图3中所示。
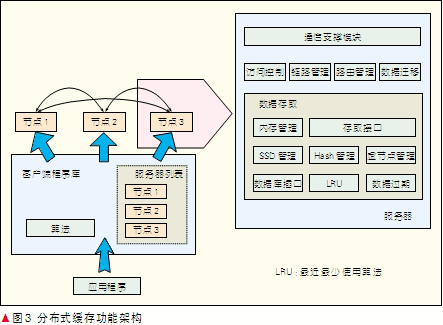
数据服务节点主要分成3个层次:通信支撑层、数据处理层和数据存取层。
- 通信支撑层主要负责通信协议适配,根据数据处理层中路由链路管理模块的指示进行端口的侦听和主动建链,同时完成底层通信数据包的发送和接收。
- 数据处理层包括路由链路管理模块、访问控制处理模块以及数据迁移控制模块。
- 数据存储层提供内存/SSD/硬盘介质的三级存储管理,具体可以根据应用的要求进行不同的配置。内存管理关注内存分配的效率以及如何避免内存碎片的形成,并根据数据访问频度进行最近最少使用算法(LRU)控制。SSD和硬盘存储模式在保证访问性能的同时提供数据的持久化存储,在这两种存储模式下数据不会随着服务节点重新启动而丢失。数据存储层提供数据生存期管理机制,能够自动清理过期数据。
2.3 分布式缓存关键技术
分布式缓存在保证数据访问可靠性、最终一致性的同时对应用提供高吞吐、低时延的访问服务,通过增加数据服务节点即能实现处理能力的性能扩充,扩容过程对应用访问完全透明。下面对分布式缓存涉及的关键技术进行介绍。
2.3.1 NRW多副本机制
分布式缓存通过多副本机制实现数据访问的可靠性,同时多个副本之间的数据同步又会带来性能和一致性的问题。我们采用NRW多副本技术来保证数据在可靠性、高性能访问以及最终一致性之间取得平衡。
图4是NRW机制的示意图,其中N是一个数据的副本数,R代表一次成功的读取操作中最小参与节点数量,W代表一次成功的写操作中最小参与节点数量。当分布式缓存的访问模型满足R+W >N时就能保证数据访问的可靠性和一致性。
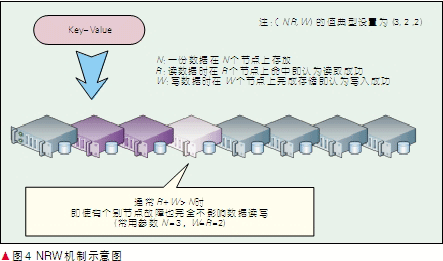
R和W直接影响性能、可用性和一致性。如果W设置 为 1,则分布式缓存集群中只要有一个节点可用,就不会影响写操作;如果R 设置为1,则分布式缓存集群中只要有一个节点可用,就不会影响读请求。但显而易见R 和W值过小都会对影响数据访问的性能和可用性,为兼顾性能、可用性和一致性,这两个值一定要合理设置。
2.3.2 一致性Hash和虚节点
一致性Hash需要首先求出分布式缓存数据服务器(节点)的哈希值,并将其配置到0~232的圆上,用同样的方法求出存储数据的键的哈希值,并映射到圆上。然后从数据映射到的位置开始顺时针查找,将数据保存到找到的第一个服务器上。如果超过232仍然找不到服务器,就会保存到第一台缓存数据服务器上。
因为数据节点服务器的机型并不统一,其性能和容量是不同的,可以使一个物理节点负责多个Hash区间的处理,使高端机器能够被充分利用。在出现热区时,可以将过热的Hash区间以虚拟节点的方式放在负荷较低的物理节点上。
分布式缓存平台结合了一致性Hash和虚拟节点的特点并加以改进,形成了如图5的方案:将232的Hash空间等分为若干分片,每个分片即是一个虚节点,根据各物理节点性能差异配置处理不同数量的虚节点,这些虚节点在物理节点上的部署关系即形成虚节点的路由。
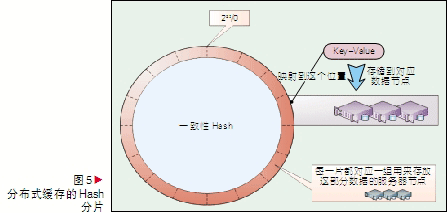
通过一致性Hash和虚节点相结合的方式,实现了数据在集群的均匀分布,同时也实现了数据服务器节点热点的消除。
2.3.3 智能路由交换
路由是指分布式缓存集群中虚节点在数据服务节点上的分布情况。分布式缓存平台构建了一个分布式锁同步系统来存放全局路由表,这张路由表是分布缓存集群路由管理的基准表,路由变更时必须要首先修改这张路由表中对应的路由记录。
为避免每次路由查找都需要查询分布式锁服务,各数据服务节点在本地同时存储全局路由表,路由查找时可直接在本地进行。这样带来的一个问题是本地路由记录可能已经过期,因此在路由记录中增加修改时间戳来进行路由记录版本的控制,举例说明:
(1) 第10号虚节点的路由信息是:存在3个副本,依次存放在服务节点A、B、C上,该条路由信息在集群中所有节点本地都有存储。
(2) A节点发生故障宕机,在A宕机期间,操作员对10号虚节点的路由记录进行了手工调整:仍然是3个副本,依次存放在服务器节点A 、D、C上,集群中除A节点外都完成了本地路由记录的更新。
(3) 此后A恢复了服务,A节点本地10号虚节点的路由记录成为一个过期的记录,当A节点收到落在10号虚节点上的数据读写请求时,就会对B、C节点的副本进行访问,访问时会带上本地10号路由记录的时间戳,B、C节点收到访问请求后会立即通知A路由信息已经过期,通过这样的路由交换机制,A快速地完成了本地路由记录更新。
上述例子中路由交换是通过数据访问请求被动触发,同时集群中每个节点的路由管理模块也会定时启动路由交换,通过这种类似病毒传染式的智能路由交换,路由变更能在集群所有节点中快速生效。客户端API的路由记录也采用同样的方式:客户端API本地缓存路由信息表,在数据访问的同时完成和服务节点的路由交换,大大提高了路由查找的效率,降低了数据访问的时延。
2.3.4 成员关系维护和故障检测
分布式缓存将节点分成两类:种子节点和普通节点。
种子节点是系统配置时,需要预先从所有节点中选出若干个节点,它们的职责是指挥系统的链路建立和拆除等。
普通节点启动后,根据配置向种子节点主动建链,种子节点对连接上的普通节点进行统一管理,根据一定的原则比如按照IP数值的大小,通知普通节点完成互相之间的建链,种子节点互相之间也根据这个原则完成两两之间的连接。图6描述集群成员关系建立的过程。
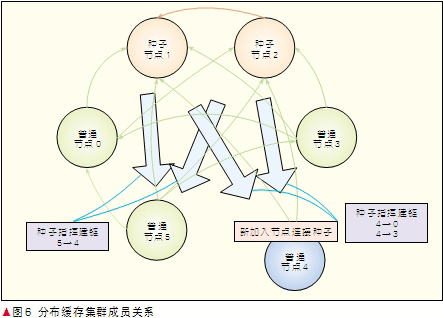
(1) 分布式缓存当前有节点1、2、3、5共4个节点,相互之间两两存在链路,节点1、2是种子节点,节点0、3、5是普通节点。
(2) 普通节点4新加入缓存集群,它首先根据配置主动连接种子节点1和节点2。
(3) 种子节点1发现当前有普通节点0、3、5和它建立了链路,当普通节点4连接成功后,它根据节点大小原则指挥节点4连接普通节点 0 和3,同时指挥原有普通节点5连接节点4。
分布式缓存通过上述机制维护集群中节点的成员关系,最终在各节点间形成网状的全连接模型,两两之间具备通信链路,任何节点故障和恢复都能够快速被集群中其他节点检测到。
3 分布式缓存助力物联网平台云化
3.1分布式缓存的优势和解决的问题
分布式缓存具有明显的技术优势。分布式的架构从架构上保证了良好的扩展性,当性能不够时,可以轻松地通过添加新节点的方法扩展性能;因为良好的扩展性,所以分布式缓存的容量可以随着节点规模的增大而呈线性增加,容量不会成为系统的瓶颈;分布式缓存采用的是基于Key-Value的简单存储方式,缓存的架构和以内存为基础的访问方式使得分布式缓存性能非常高,单节点每秒可以达到24万多次的读写操作;分布式缓存所使用的多份副本复制的方法,避免单点故障;同时无中心化的架构和一致性Hash的数据分布算法,使得局部节点的损坏不会影响整体集群的可用性,把故障的影响降到最低。
目前的应用在部署运行过程中常会遇到一些问题:第一,单节点不能满足性能要求时,需要扩展到多个节点,通常采用按号段的方式进行扩展,此种扩展方式不具有通用性,与各个应用密切相关,开发和维护的成本也较高;第二,在不同的物理节点的应用上共享数据,通常通过文件的方式或同步的方式进行共享,但是这在性能和一致性的处理上存在较大的风险和困难;第三,因为多个节点同时访问数据库,使得数据库和磁盘I/O成为系统的瓶颈,通常使用单节点的缓存方式来解决,这样一方面会造成系统资源的浪费,另一方面也使各个节点中缓存一致性的处理也非常复杂;第四,应用节点的应用程序意外退出重启动后,如何保证已有的会话不掉线,往往通过写文件的方法实现,这时磁盘I/O以及系统初次的加载都存在性能瓶颈。把分布式缓存引进应用后,可以方便地帮助应用解决这些问题。应用通过调用分布式缓存提供的API接口,把关键的数据放到分布式缓存中,而自身重点关注应用逻辑的处理,这样可以轻松打造出高性能的、可扩展的、高可靠的分布式应用系统,通过标准接口的封装,对外提供云服务。
3.2 分布式缓存在物联网中的应用
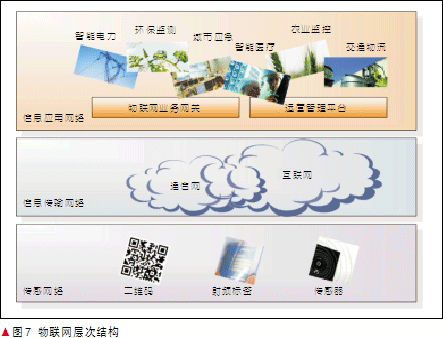
物联网的出现是信息通信技术(ICT)的新挑战。物联网无所不在,它可以使所有的物体,从洗衣机到冰箱、从房屋到汽车通过物联网进行信息交换。物联网技术融入了射频识别(RFID)技术、传感器技术、纳米技术、智能技术与嵌入技术。物联网技术将是改变人们生活和工作方式的重要技术。物联网主要包括3个层次,如图7中所示。第1个层次是传感器网络,也就是目前所说的包括RFID、条形码、传感器等设备在内的传感网,主要用于信息的识别和采集;第2个层次是信息传输网络,主要用于远距离无缝传输来自传感网所采集的巨量数据信息;第3个层次是信息应用网络,该网络主要通过数据处理及解决方案来提供人们所需要的信息服务。
物联网业务网关属于第3个层次,如图8所示。它是实现物联网应用和物联网终端智能连接的桥梁,能够提供接入认证、智能路由、业务计费、能力接入、服务质量(QoS)服务保障等核心功能。支持通用分组无线业务(GPRS)、短信、有线接入等多种网络接入方式。物联网业务网关汇聚所有的机器到机器(M2M)终端消息,除了支持标准协议终端的消息处理外,对非标准协议终端也提供IP层路由转发和业务鉴权功能。因此对业务网关相关的性能提出了极高的要求。
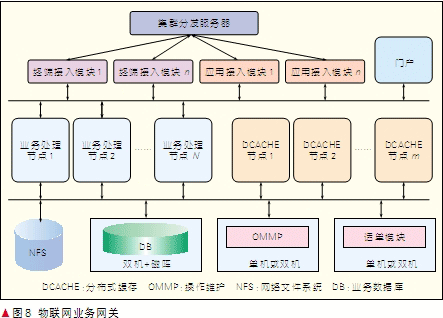
中兴通讯物联网业务网关采用多模块架构,通过引入云计算分布式缓存平台,使其具有极高的吞吐率,保证了网关的高并发处理能力,系统在两个刀片机框满配置的情况下,可达到18万条/秒的报文转发速率。分布式缓存的应用,使系统支持数据动态迁移,在个别节点故障不会造成事务的中断。
4 结束语
物联网与云计算存在着密不可分的关系。一方面,物联网的发展离不开云计算的支撑。从量上看,物联网将使用数量惊人的传感器(如数以亿万计的RFID、智能尘埃和视频监控等),采集到的数据量惊人。这些数据需要通过无线传感网、宽带互联网向某些存储和处理设施汇聚,而使用云计算分布式缓存等系列技术来承载这些任务具有非常显著的性价比优势;从质上看,使用云计算系列技术对这些数据进行处理、分析、挖掘,可以更加迅速、准确、智能地对物理世界进行管理和控制,使人类可以更加及时、精细地管理物质世界,从而达到“智慧”的状态,大幅提高资源利用率和社会生产力水平[6]。可以看出,云计算凭借其强大的处理能力、存储能力和极高的性能价格比,很自然就会成为物联网的后台支撑平台。另一方面,随着物联网针对智能交通、智能医疗、智能电网等领域解决方案的落地,物联网将成为云计算最大的用户,为云计算系列技术取得更大商业成功奠定基石。
5 参考文献
[1] 刘鹏.云计算[M].北京: 电子工业出版社, 2010.
[2] 陈明,王锁柱.物联网的产生与发展[J].计算机教育, 2010(12):1-3.
[3] DECANDIA G, HASTORUN D, JAMPANI M,et al. Dynamo: Amazon’s Highly Available Key-Value Store[C]//Proceedings of the 21th ACM SIGOPS Symposium on Operating Systems Principles (SOSP’07), Oct 14-17, 2007, Washington, DC, USA. New York, NY, USA: ACM, 2007:205-220.
[4] CHANG F, DEAN J, GHEMAWAT S,et al. Bigtable: A Distributed Storage System for Structured Data[C]//Proceedings of the 20th ACM SIGOPS Symposium on Operating Systems Principles (SOSP’05), Oct 23-26, 2005, Brighton UK. New York, NY, USA: ACM, 2005: 205-218.
[5] LAKSHMAN A,MALIK P.Cassandra: A Decentralized Structured Storage System[J]. SIGOPS Operating Systems Review,?2010, 44(2):35-40.
[6] 邬贺铨.物联网的应用与挑战综述[J].重庆邮电大学学报(自然科学版),2010,22(5): 526-531.
收稿日期:2011-05-25
[摘要] 物联网是信息技术发展到一定阶段的产物,而云计算平台是物联网应用的基础。文章从当前云计算应用所面临的问题和缺陷出发,介绍了云计算分布式缓存的部署方式、功能架构及关键技术,并说明了分布式缓存高性能、高吞吐、高可靠性、高扩展性等优势和特性。文章解决了物联网应用普遍面临的数据可靠性、大容量内存共享、多模块数据一致保障、线性扩容等难题,为物联网平台云化架构的底层支撑奠定了基础。
[关键词] 云计算;物联网;分布式缓存
[Abstract] The Internet of Things (IoT) is the product of information technology, and the cloud computing platform is the basis of IoT applications. This paper discusses the deployment, functional architecture and key technology of cloud computing distributed cache, which can be used to overcome certain IoT shortcomings. This paper focuses on the advantages of distributed cache, including high performance, throughput, reliability, and scalability. Cloud computing distributed cache can solve IoT application problems that affect data reliability, large shared memory, consistency in multimodule data protection, and linear expansion. These support the bottom layer of cloud architecture in the IoT platform.
[Keywords] cloud computing; Internet of things; distributed cache
.png)

.png)

.png)


