下一代互联网中名系统的研究
发布时间:2010-09-28
作者:林福宏,陈常嘉
基金项目:国家重点基础研究发展规划(“973”计划)课题(2007CB307100)
在当前互联网应用中,命名和相对应名字的解析映射起着极为重要的作用。有了对资源的命名,它在网络上的注册才成为可能;有了名字的解析映射,资源的查询才成为可能。目前,命名采用域名的方式,而名字解析采用域名解析系统(DNS)来实现。DNS初始设计的目的是将不容易记忆的IP地址映射为更容易记忆的带有语义的字符串[1],以方便用户。在应用初期,DNS的优势得到了很好的体现,迅速成为了全球最大的域名解析系统。然而由于其设计初期考虑的比较简单,所以在当今应用中出现了很多问题。具体表现在:
(1) DNS根服务器作用重大,所有本地DNS服务器无法解析的域名解析请求都要直接送到DNS根服务器中,而这些DNS根服务器的最终管理权与控制权在美国政府手里,美国可以对DNS根服务器中的ROOTZONE文件记录进行修改,从而使得一些国家从互联网世界中消失[2]。
(2) 域名带有语义,不可避免地涉及到所有权归属问题,从而带来不必要的法律纠纷[3]。
(3) DNS面向主机,当主机中的数据移动或复制后,DNS则无法再次为该数据提供服务[4]。
(4) 在DNS服务器中,由于业务需要,负责.com域名解析的服务器比负责.org等域名解析的服务器负载重很多[5],没有相互协调充分利用网络资源。
1 学术界提出的新名系统
针对以上DNS名系统中的缺点,学术界提出了新的名系统,主要代表是文献[6]。下面介绍这套系统的工作方式。
名字的生成采用Hash方式,其过程为:提取资源的元信息;Hash元信息生成一个字符串,用这个字符串来标识资源。由于名字的生成过程是基于资源的元信息,所以名字不会随资源的移动或复制而改变,对用户来说是透明的,可以用始终如一的名字查找到资源。这样可以很好地解决现有命名方式中存在的不足。
名字解析映射系统采用分布式哈希表(DHT)结构,而DHT提供一种操作:给定一个关键字,把这个关键字经Hash映射到系统的某个唯一节点上。在文献[6]中,将DHT中的节点看成解析映射服务器。在名字注册时,将元信息当作关键字经Hash产生的名字注册到DHT上;在名字解析时,利用元信息生成的名字在DHT上解析返回连接信息。由于DHT的扁平状结构,当解析映射系统受到DoS攻击时,瘫痪的只是被攻击的那台服务器,其他服务器的并没有受到影响。所以,在同样的DoS攻击下,这种系统的鲁棒性要强于DNS。但是对于DHT来说,解析一个名字所花费的最大时延为log N(以Chord为例),其中N为系统中节点数。对于一个全球系统来说,N的值会在百万级,这时解析时延太大不适实际环境的使用。
为此我们设计了两种新的名系统,在保留文献[6]系统优势的基础上,解决解析时延太大的问题。命名为基于One-hop DHT的名系统,重叠化名系统。
2 设计基于One-hop DHT的名系统
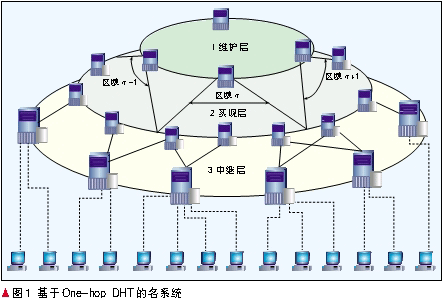
基于One-hop DHT的名系统,有一个重叠结构并主要由3层组成(如图1所示):中继层、实现层和维护层。其中,中继层的主要功能是控制用户的接入,及处理用户注册或查询资源名字的请求;实现层和维护层联合工作,实现各种资源名字的注册与查找,其中实现层维护一个Chord系统,而维护层维护一个向量空间(向量空间是指某一个服务器知道该层其它服务器的所有信息)。
2.1 新名系统具体的实现方案
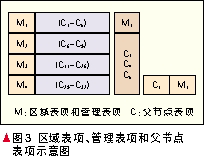
中继层上各节点分别与实现层上1-3个节点相连,通过这些相连的节点进入系统注册或获取服务所需的连接信息。实现层维护一个Chord环,该层中的各节点维护两组表项:父节点表项和路由表项。其中,路由表项与原Chord算法中实现方式一致(由文献[7]给出),而父节点表项内容为管理该节点的维护层节点ID。维护层维护两组表项:区域表项和管理表项。区域表项是用于维护实现层的一部分连续区域,而管理表项则用于指示在这个区域内有哪几个节点存活。
下面用一个例子简要说明该映射系统的整个工作过程。如图2所示,在这个映射系统中,维护层有4个维护节点,实现层有11个节点,中继节点有2个,具体连接方式如图2所示。图3中列举了几个具有代表性的表项:M1的区域表项和管理表项,C1的父节点表项。
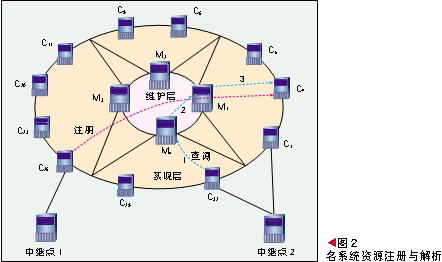
2.1.1 资源的注册:
(1) 将此请求发送到一个中继点(中继点1)。
(2) 中继点提取此项服务的元信息,经过Hash元信息生成一个新的网络名字(SID1=3)。
(3) 通过实现层接入点Chord节点C26,并利用Chord算法直接将该名字注册到Chord环上,即将这项服务的名字应用于建立连接的信息并入节点C4。
2.1.2 资源的解析:
(1) Hash服务的元信息生成网络名字(SID1=3)。
(2) 发送到一个中继点(例如中继点2)。
(3) 中继点通过它在实现层的接入点C1或C32将该网络名字送往上层(假设此处选择C32)。
(4) 节点C32收到该服务请求后直接递交给它的父节点M4,不做任何其他处理。
(5) 节点M4查询其区域表项,发现新网络名字3在维护节点M1管理的区域内,将该请求发送到节点M1。
(6) 节点M1收到该服务请求后,查询其管理表项并将发现的新网络名字为3的信息存储在节点C4上面,于是M1与节点C4建立连接,取得获取此项服务所需的连接信息按原路返回给用户。
(7) 用户利用返回的连接信息与服务提供商建立连接获取服务。
在整个实现过程中,我们在注册过程中没有使用维护层,只在查询过程中使用了维护层。我们认为在网络应用中主要的瓶颈在于查询端,这样做可以提高查询效率。因为维护节点只需要处理查询请求,而不用对注册请求作处理。
一般情况下,维护层节点会有热备份,并且鲁棒性较强。如果有故障产生,查询消息则不再发往维护层节点,而是直接在实现层利用Chord算法进行路由,以便在系统正常工作的基础上对护层节点进行修复。这样做在一定程度上提高了整个系统的鲁棒性。
One-hop DHT的名系统在一次名字解析时,最大跳数为3,降低了查询时延;但该系统只适合小范围的应用,其瓶颈在于维护层服务器的处理能力。为此,我们又设计了重叠化名系统。
3 重叠化名系统
3.1 重叠化名系统中名字的设计
新网络名字将名字分为两部分:前缀部分和资源标识部分,如图4所示。前缀部分用两个字节标识,又可分为两部分:前9个bit用于标识地理位置信息(以国家和地区为单位),后7个bit用于携带服务质量(QoS)信息或备用。因为目前全世界有200多个国家和地区,9个bit足以唯一标识任何一个国家;后7个比特可以带一些QoS信息或做扩展服务等。资源标识部分用于标识资源,它产生于资源的元信息。元信息经过Hash运算后生成一个160 bit的字符串来唯一标识所描述的资源。
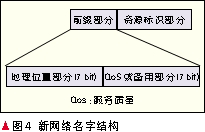
由于名字的资源标识部分的生成过程是基于资源的元信息,所以与文献[4]一样,名字不会随着资源的移动或复制而改变,用户可以用始终如一的名字查找到资源。这样的操作方法很好地解决了数据的移动和复制问题。
我们定义的名字结构中,包含了地理位置部分,可以缩小资源解析范围;而QoS部分,可以使得网络名字带有QoS信息,方便用户选择符合自己要求的资源。
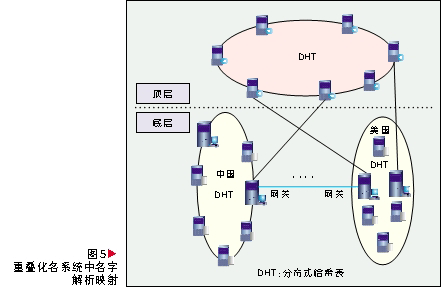
3.2 重叠化名系统中解析映射系统的设计
我们设计的名字解析映射系统主要分为两层,如图5所示。顶层具有全球性,并采用DHT结构,主要作用是维护和管理全球的名字;下层具有局域性,可以以国家为单位,采用DHT结构作为路由形式,主要用于处理本域内的名字解析,以及与上层、其它域的交互。在下层网络中,主要有两类服务器:平常服务器和网关服务器。对于平常服务器,其名字注册和解析方式与本身DHT算法保持一致;对于网关服务器,在维持原来路由表的基础上,增加了两个路由表:一个用于指向上层服务器;另一个用于指向其它域内的网关服务器。
3.2.1 资源的注册
资源注册过程就是生成名字并注册到名字解析系统的过程,主要有以下几个步骤:
(1) 提取资源的元信息。
(2) 将提取到的元信息Hash生成名字的资源标识部分。
(3) 将所在国家代码填入地理位置部分。
(4) 将自己所在的区域信息或QoS信息等填入备用或国内自定义段(备用时可以不填)。到此为止已生成了一个合法的名字,下面将名字注册到名字解析系统中。
(5) 根据本身域内的算法将名字和连接信息注册到域内某个平常服务器上。
(6) 经过距离自己最近的网关服务器将名字及连接信息注册到上层DHT上。
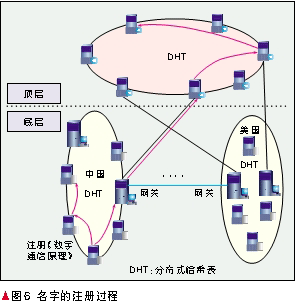
下面用一个例子说明这个过程,如图6所示。中国一家服务提供商需要注册《数字通信原理》这本书。首先提取它的元信息,如“数字通信原理”;Hash元信息生成一个160 bit的字符串101010101111…001;提取“中国”的代码111000100;填入QoS信息,如QoS等级为3——0000111;合并到一起生成一个合法名字1110001000000111101010…001。
3.2.2 资源的解析
资源的解析过程就是通过网络名字获取连接信息的过程。这个过程中可能包含两种情况:资源请求者知道所请求资源的存储地;资源请求者不知道所请求资源的存储地。对于第一种情况又可以分为两类:资源存储地在本国和本国外的其它国家时。下面分别介绍各种解析方式,如图7所示。
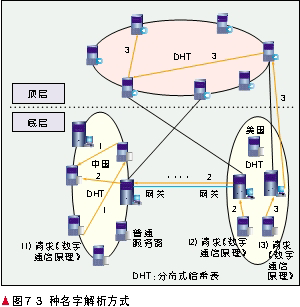
(1) 当请求的资源在本国时:Hash资源的元信息生成名字的资源标识部分,此时将国家信息填入地理位置部分,将QoS信息填入QoS或备用部分,即可生成一个合法的名字;在平常服务器接入点,利用生成的资源标识部分,在本国所采用的DHT结构中可以找到该资源所对应的连接信息。
(2) 当请求的资源在其它国家时:Hash资源的元信息生成名字的资源标识部分,此时将国家信息填入地理位置部分,将QoS信息填入QoS或备用部分,即可生成一个合法的名字;在平常服务器接入点,将该名字递交给最近的网关服务器,网关服务器利用地理位置部分解析该名字所在国家的一个网关服务器,并将此请求递交给它;收到请求的网关服务器采用自己域内的DHT路由形式找到这个资源所对应的连接信息。
(3) 当不清楚资源存储地时:Hash资源的元信息生成名字的资源标识部分,此时将地理位置部分填入000000000,QoS信息填入QoS或备用部分,则会生成一个合法的名字;在平常服务器接入点,将该名字递交给最近的网关服务器,网关服务器将该请求发送到上层DHT上,上层DHT利用自己的路由算法,将资源标识部分解析为连接信息。
3.3 时延分析
本节将分析各种情况下的网络解析时延,在文献[8]中提到网络时延主要是由跳数引起的。下面将以跳数为度量单位研究我们设计的名字解析映射系统的时延性能。在该系统中,一次解析时延可以分为3种情况:
(1) 域内解析:名字解析请求只需要在本域内解析。所需最大跳数为logN1(以域内服务器组织形式为Chord为例),其中N1代表的是域内服务器数量。
(2) 域间解析:名字解析请求发送到本域网关节点,网关节点再转发到相对应邻域的网关节点上,邻域网关节点负责解析该名字。所需最大跳数为2+ log N2,其中N2为领域内服务器数量。
(3) 路由到顶域解析:名字解析请求发到本域网关节点,网关节点再利用顶域路由表进行名字解析。所需要的最大跳数为log N3,其中N3为顶域服务器数量。假设上述3种情况的比例为p 1、p 2、 p 3则该系统解析时所需最大跳数为:
T Hop = p1log N1+ p2(2+log N2)+ p3log N3
参数设置:为了方便分析,假设全世界每个国家所需要处理的名字一样多。每个国家可设置50个网关服务器,贡献50台顶域服务器,则顶层DHT系统由1万个服务器组成。3种名字解析方式——域内解析、域间解析和顶层解析,假设其所对应的比例为98%、1%、1%。
T Hop = 0.98log 1000+0.01(2+
log 10000)+ 0.01log 10000
= 0.98×13.287+0.01×13.287
= 13.307
在文献[6]中提到用Chord环直接代替DNS,实现名字的解析映射。当处理同样数目的名字解析,即服务器数量与重叠化名系统相当时,解析一个名字请求所需的最大跳数为:
T’Hop = log(200×10000)= 20.9316
比较T Hop 和T’Hop可得:新的解析系统在性能方面要优于文献[6]所设计的系统。
4 设计优势
上述两种名系统主要有以下几方面的好处:
(1) 消除了某个国家对解析系统的完全控制,使得各个国家都能和平利用该网络资源。一方面映射系统节点可以至少在每个国家部署一个,整个系统为全球用户共同服务;另一方面注册到名字映射系统中的网络名字是一个没有语义的字符串,从中不能显示出任何实际意义,从根本上消除了某个国家对解析系统的完全控制,因此将政治因素从网络应用中剥离出去。
(2) 该映射系统是以一个元信息Hash生成的值作为新网络名字在系统中注册与查询。从这方面看,主要有两个好处:新服务可以提取自己的元信息生成新的网络名字,在服务映射系统中注册与查找。可以说该解析系统为新服务的接入提供了恰当的接口,新的网络名字是一个没有实际意义的Hash值,不带有语义,所以就不会产生所有权归属纠纷。
(3) 在现有网络应用中,数据的复制和移动是不可避免的,而现行网络技术不能很好地解决该问题。当一个数据移动后,再重新注册它,则必然得到的全新的域名。对于用户来说需要很长时间才能获得此全新的域名,因此上网时常会出现“Http 404错误”。于是研究者设计了Http重定向,它可以解决数据在一个域内的移动问题,然而对于域间的移动没有很好的解决方案。在我们设计的映射系统中,新的网络名字是用数据的同一个元信息生成的。所以,当数据移动后对该数据重新注册,所用的新网络名字是仍然是原来的。对于用户端来说,过程完全是透明的,不会感觉到数据已经发生移动或复制,应用原来的网络名字进行解析映射就可以获得此项服务的连接信息。
5 结束语
文章首先介绍了现有名系统DNS存在,如:含有语义信息、不支持数据的移动和复制、动态负载不均衡等。针对以上缺点,学术界提出采用结构化DHT来做名系统,它很好地消除了这些缺点。但是带来了一个新的问题:一次解析时延太大,不适合于实际应用。为此我们设计了两种新的方案来综合DNS名系统以及DHT名系统的优点——基于One-hop DHT的名系统,重叠化名系统。
基于One-hop DHT的名系统采用三层环结构,分别实现用户接入的控制、资源名字的注册与资源名字的解析。由于该名系统上层极少节点负责整个查询,因此,只能适应于小环境应用。重叠化名系统采用分域处理,可以在全球范围内应用,在每一个国家维护一个DHT名系统的基础上,全球维护一个大DHT系统。这两套系统一方面可以消除DNS名系统存在的缺陷,如不支持数据的移动和复制等;另一方面又降低了DHT名系统解析时延太大的缺点。最后通过理论分析证明这两套系统适于实际环境应用。
6 参考文献
[1] MOCKAPETRIS P, DUNLAP K J. Development of the domain name system [C]//Proceedings of Conference on Applications, Technologies, Architectures, and Protocols for Computer Communications (SIGCOMM’08), Aug 17-22, 2008, Seattle, WA, USA. New York, NY,USA: ACM, 1988:123-133.
[2] 曹蓟光. 互联网域名系统管理新机制的研究 [J]. 电信网技术, 2005(10):8-12.
[3] WALFISH M, BALAKRISHNAN H, SHENKER S. Untangling the Web from DNS [C]//Proceedings of the 1st Conference on Symposium on Networked Systems Design and Implementation(NSDI'04), Mar 29-31,2004, San Francisco, CA,USA. Berkeley, CA, USA: USENIX Association, 2004:225-238.
[4] BALAKRISHNAN H, LAKSHMINARAYANAN K, RATNASAMY S, et al. A layered naming architecture for the internet [C]//Proceedings of Conference on Applications, Technologies, Architectures, and Protocols for Computer Communication(SIGCOMM’04), Aug 30-Sep 3,2004, Portland, OR, USA. New York, NY,USA: ACM,2004:343-352.
[5] STOICA I, MORRIS R, LIBEN-NOWELL D, et al. Chord: A scalable peer-to-peer lookup protocol for internet applications [J]. IEEE/ACM Transactions on Networking, 2003,11(1):17-32.
[6] RAMASUBRAMANIAN V, EMIN G S. The design and implementation of a next generation name service for the internet [C]// Proceedings of Conference on Applications, Technologies, Architectures, and Protocols for Computer Communication(SIGCOMM’04), Aug 30-Sep 3,2004, Portland, OR, USA. New York, NY,USA:ACM,2004:331-342.
[7] STOICA I, MORRIS R, LIBEN-NOWELL D, et al. Chord: a scalable peer-to-peer lookup protocol for internet applications [J]. IEEE/ACM Transactions on Networking, 2003,11(1):17-32.
收稿日期:2010-03-31
[摘要] 学术界近期提出了基于扁平结构的分布式哈希表(DHT)名系统,用以克服现有名系统域名解析系统(DNS)存在的缺陷,如不支持数据的移动、复制等,但由于其解析时延较大,不适于实际应用。为此,综合DNS名系统及DHT名系统的优点,设计了两种新的系统:第一种系统采用One-hop DHT形式,三层环结构实现,适于小环境应用;第二种采用混合结构DHT形式,分域实现,适于全球性应用。经理论分析证明这两套系统在实际应用中是可行的。
[关键词] 名系统;域名解析系统;分布式哈希表;命名;名字解析映射
[Abstract] Academics recently proposed a new naming system based on the flat structured domain name system (DNS) to overcome defects in the existing DNS. Such defects include the inability to support movement and replication. Due to lengthy time delay, DNS is not suitable for practical application. This paper introduces two improved structures which combine the advantages of DNS and DHT. The first system uses one-hop DHT form and three ring structure (suitable for smaller environments), while the second adopts a hybrid structure of DHT and Fenwick (suitable for global application). Through theoretical application, it is proven that these systems are feasible for practical use.
[Keywords] naming system; DNS; DHT; naming; name resolution mapping
.png)

.png)

.png)


